
高可用架构Sentinel
Sentinel 架构体系
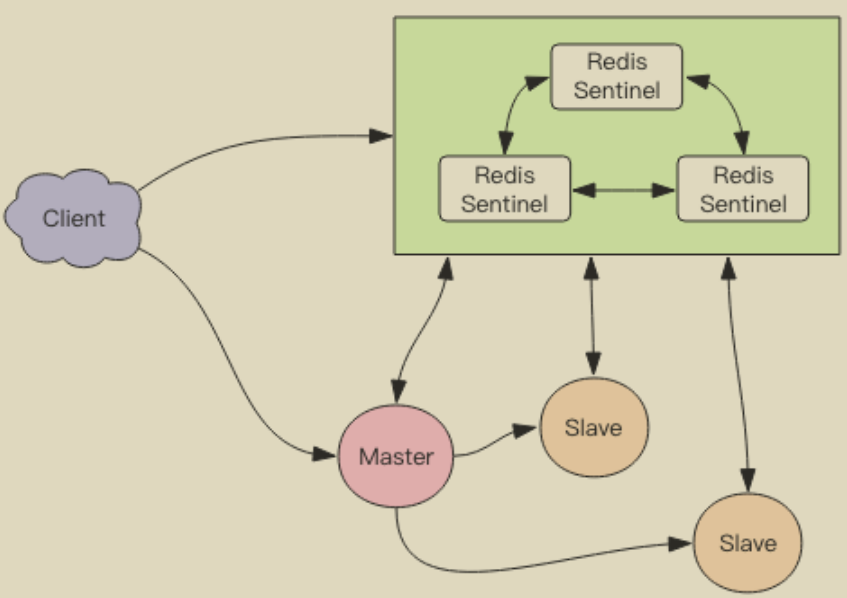
可以将 Redis Sentinel 集群看成是一个 ZooKeeper 集群,它是集群高可用的心脏,它一般是由 3~5 个节点组成,这样挂了个别节点集群还可以正常运转。它负责持续监控主从节点的健康,当主节点挂掉时,自动选择一个最优的从节点切换为主节点。客户端来连接集群时,会首先连接 sentinel,通过 sentinel 来查询主节点的地址,然后再去连接主节点进行数据交互。当主节点发生故障时,客户端会重新向 sentinel 要地址,sentinel 会将最新的主节点地址告诉客户端。 如此应用程序将无需重启即可自动完成节点切换。比如上图的主节点挂掉后,集群将可能自动调整为下图所示结构。
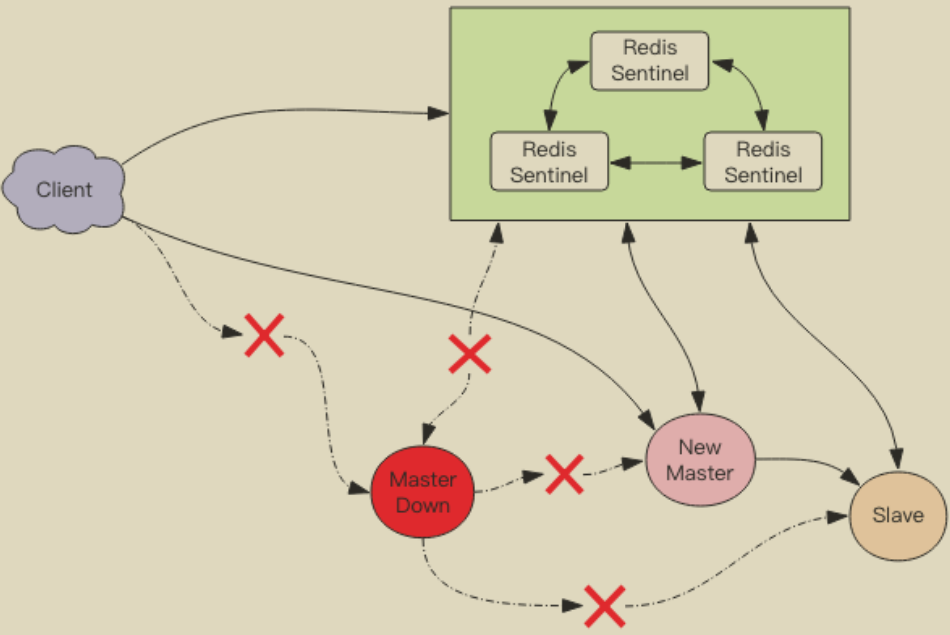
主节点挂掉了,原先的主从复制也断开了,客户端和损坏的主节点也断开了。从节点被提升为新的主节点,其它从节点开始和新的主节点建立复制关系。客户端通过新的主节点继续进行交互。
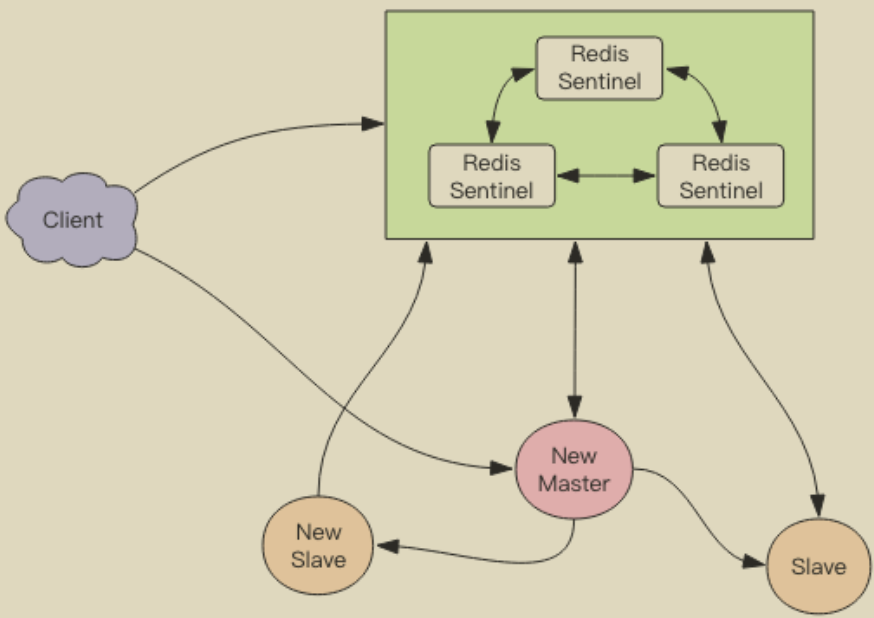
Sentinel 会持续监控已经挂掉了主节点,待它恢复后,此时原先挂掉的主节点现在变成了从节点,从新的主节点那里建立复制关系。
Sentinel 搭建
# 创建目录
[root@localhost redis-replication]# mkdir /usr/local/redis-replication
# 新建三个目录
[root@localhost redis-replication]# cd /usr/local/redis-replication/
[root@localhost redis-replication]# mkdir 6379 6380
6381
# 复制配置文件
[root@localhost redis-replication]# cp /test/redis-4.0.6/redis.conf /usr/local/redis-replication/6379/
[root@localhost redis-replication]# cp /test/redis-4.0.6/redis.conf /usr/local/redis-replication/6380/
[root@localhost redis-replication]# cp /test/redis-4.0.6/redis.conf /usr/local/redis-replication/6381/
# 修改配置文件 6379
[root@localhost 6379]# vim /usr/local/redis-replication/6379/redis.conf
bind 0.0.0.0
port 6379
logfile "6379.log"
dbfilename "dump-6379.rdb"
daemonize yes
rdbcompression yes
[root@localhost 6379]# /test/redis-4.0.6/src/redis-server /usr/local/redis-replication/6379/redis.conf
# 修改配置文件 6380
[root@localhost 6379]# vim /usr/local/redis-replication/6380/redis.conf
bind 0.0.0.0
port 6380
logfile "6380.log"
dbfilename "dump-6380.rdb"
daemonize yes
rdbcompression yes
slaveof 192.168.31.220 6379
[root@localhost ~]# /test/redis-4.0.6/src/redis-server /usr/local/redis-replication/6380/redis.conf
# 修改配置文件 6381
[root@localhost 6381]# vim /usr/local/redis-replication/6380/redis.conf
bind 0.0.0.0
port 6381
logfile "6381.log"
dbfilename "dump-6381.rdb"
daemonize yes
rdbcompression yes
slaveof 192.168.31.220 6379
[root@localhost redis-replication]# /test/redis-4.0.6/src/redis-server /usr/local/redis-replication/6381/redis.conf
# 查看进程
[root@localhost redis-replication]# ps -ef | grep redis
root 41580 1 0 12:55 ? 00:00:00 /test/redis-4.0.6/src/redis-server 0.0.0.0:6381
root 41613 36413 0 12:55 pts/3 00:00:00 grep --color=auto redis
root 54093 1 0 04:59 ? 00:00:15 /test/redis-4.0.6/src/redis-server 0.0.0.0:6379
root 55430 1 0 05:04 ? 00:00:22 /test/redis-4.0.6/src/redis-server 0.0.0.0:6380
# 登录6379查看
[root@localhost ~]# /test/redis-4.0.6/src/redis-cli -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.31.220,port=6381,state=online,offset=322,lag=0
slave1:ip=192.168.31.220,port=6380,state=online,offset=322,lag=1
# 复制sentinel配置文件
[root@localhost ~]# cp /test/redis-4.0.6/sentinel.conf /usr/local/redis-replication/sentinel_1.conf
# 修改sentinel配置文件
[root@localhost redis-replication]# vim /usr/local/redis-replication/sentinel_1.conf
sentinel monitor mymaster 192.168.31.220 6379 1
sentinel down-after-milliseconds mymaster 10000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1
# 启动sentinel服务
[root@localhost redis-replication]# /test/redis-4.0.6/src/redis-sentinel /usr/local/redis-replication/sentinel_1.conf
# 故障模拟 关闭6379
[root@localhost ~]# /test/redis-4.0.6/src/redis-cli -p 6379 shutdown
配置说明
- sentinel monitor mymaster 127.0.0.1 6379 1 名称为 mymaster 的主节点名,1 表示将这个主服务器判断为失效至少需要 1 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)。 如果是 3 主 3 从(需要 3 个 sentinel, sentinel monitor mymaster 127.0.0.1 6379 2 改为 2)
- down-after-milliseconds 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数(主观下线)
- failover 过期时间,当 failover 开始后,在此时间内仍然没有触发任何 failover 操作,当前 sentinel 将会认为此次 failoer 失败(客观下线)。
- parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。
- 如果从服务器被设置为允许使用过期数据集, 那么你可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求, 因为尽管复制过程的绝大部分步骤都不会阻塞从服务器, 但从服务器在载入主服务器发来的 RDB 文件时, 仍然会造成从服务器在一段时间内不能处理命令请求: 如果全部从服务器一起对新的主服务器进行同步, 那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。
Sentinel 三大任务
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
Sentinel 故障转移原理
主观下线
概念主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
- 如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复(valid reply), 那么 Sentinel 就会将这个服务器标记为主观下线。
- 服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
返回 +PONG 。
返回 -LOADING 错误。
返回 -MASTERDOWN 错误。
客观下线
指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
- 从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议: 如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。 如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。
- 客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。 只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对失效的主服务器执行自动故障迁移操作。
SpringBoot 整合 Sentinel
引入 yml 配置文件
redis:
sentinel:
master: redis_master_group1 #Master名称
nodes: 192.168.31.220:26379 #如果有多个Sentinel节点用逗号分隔
pom 文件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>