
Redis Cluster
部署 Redis Cluster
# 安装redis
cd /usr/local/
wget http://download.redis.io/releases/redis-4.0.6.tar.gz
tar -zxvf redis-4.0.6.tar.gz
cd redis-4.0.6
make && make install
# 新建集群文件夹
mkdir /usr/local/redis_cluster
cd /usr/local/redis_cluster
mkdir 7000 7001 7002 7003 7004 7005
cp /usr/local/redis-4.0.6/redis.conf /usr/local/redis_cluster/7000
cp /usr/local/redis-4.0.6/redis.conf /usr/local/redis_cluster/7001
cp /usr/local/redis-4.0.6/redis.conf /usr/local/redis_cluster/7002
cp /usr/local/redis-4.0.6/redis.conf /usr/local/redis_cluster/7003
cp /usr/local/redis-4.0.6/redis.conf /usr/local/redis_cluster/7004
cp /usr/local/redis-4.0.6/redis.conf /usr/local/redis_cluster/7005
# 修改redis_cluster/7000到redis_cluster/7005文件夹下面的redis.conf配置文件
daemonize yes //redis后台运行
port 7000 //端口7000,7002,7003,7004,7005
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-node-timeout 5000 //请求超时 设置5秒够了
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
bind 127.0.0.1 192.168.31.220 //(此处为自己内网的ip地址,centos7下面采用ip addr来查看,其他系统试一下ifconfig查看,ip为)
# 一次启动所有节点
cp /usr/local/redis-4.0.6/src/redis-server /usr/local/ redis-cluster
cd /usr/local/redis_cluster/7000 ../redis-server ./redis.conf
cd /usr/local/redis-cluster/7001 ../redis-server ./redis.conf
cd /usr/local/redis-cluster/7002 ../redis-server ./redis.conf
cd /usr/local/redis-cluster/7003 ../redis-server ./redis.conf
cd /usr/local/redis-cluster/7004 ../redis-server ./redis.conf
cd /usr/local/redis-cluster/7005 ../redis-server ./redis.conf
# 创建集群:前面已经准备好了搭建集群的redis节点,接下来我们要把这些节点都串连起来搭建集群。官方提供了一个工具:redis-trib.rb(/usr/local/redis-4.0.6/src/redis-trib.rb) 它是用ruby写的一个程序,所以我们还得安装ruby.
yum -y install ruby ruby-devel rubygems rpm-build
gem install redis
# 如果gem install redis发现报错
curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
rvm list known
rvm install 2.3.3
rvm use 2.3.3
ruby --version
gem install redis
# 开启集群工作
cd /usr/local/redis-4.0.6/src
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
# 测试集群是否正常
./redis-cli -c -p 7000
# 如果搭建失败,请用此命令将所有启动的redis server一个个关闭掉
./redis-cli -p 7000 shutdown
Redis 集群的数据分片
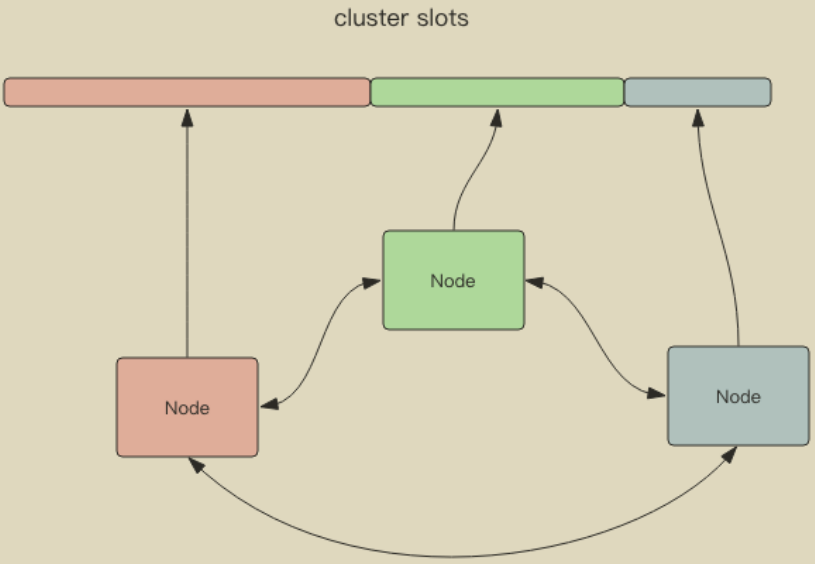
RedisCluster 是 Redis 的亲儿子,它是 Redis 作者自己提供的 Redis 集群化方案。Redis Cluster 将所有数据划分为 16384 的 slots,每个节点负责其中一部分槽位。不同槽位的信息存储于不同的节点中。
当 Redis Cluster 的客户端来连接集群时,它也会得到一份集群的槽位配置信息。这样当客户端要查找某个 key 时,可以直接定位到目标节点。客户端为了可以直接定位某个具体的 key 所在的节点,它就需要缓存槽位相关信息,这样才可以准确快速地定位到相应的节点。同时因为槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
另外,RedisCluster 的每个节点会将集群的配置信息持久化到配置文件中,所以必须确保配置文件是可写的,而且尽量不要依靠人工修改配置文件。
槽位定位算法
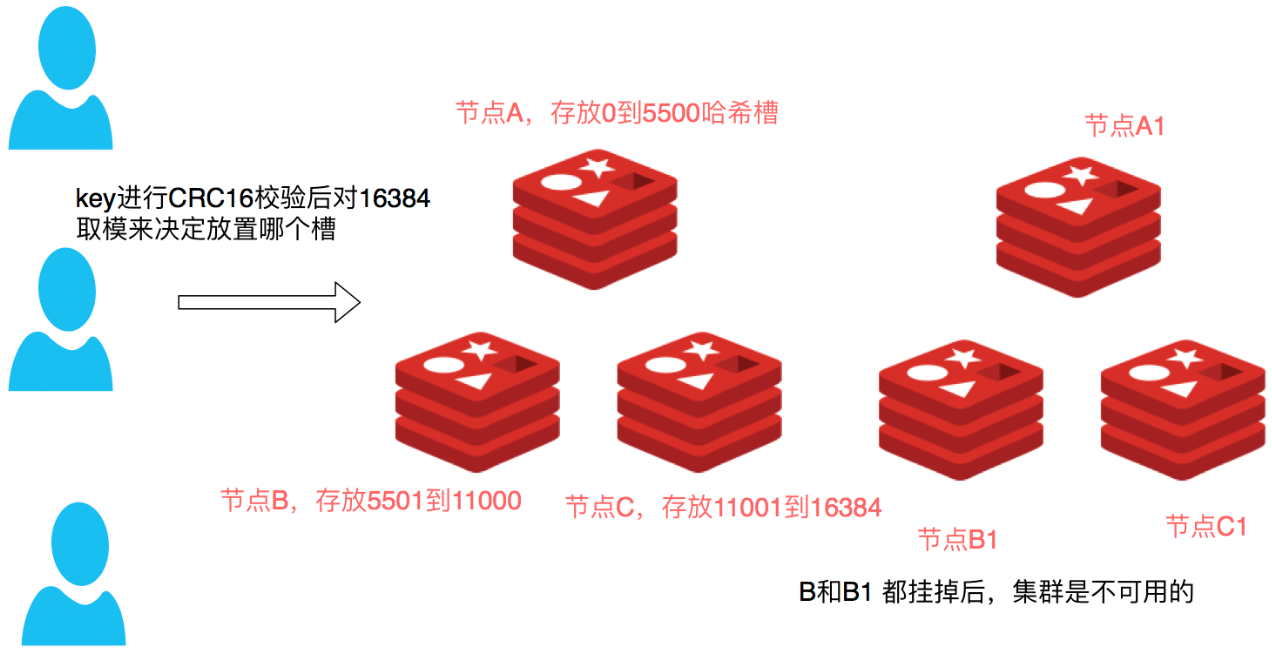
Cluster 默认会对 key 值使用 crc32 算法进行 hash 得到一个整数值,然后用这个整数值对 16384 进行取模来得到具体槽位。
Cluster 还允许用户强制某个 key 挂在特定槽位上,通过在 key 字符串里面嵌入 tag 标记,这就可以强制 key 所挂在的槽位等于 tag 所在的槽位。
跳转
当客户端向一个错误的节点发出了指令,该节点会发现指令的 key 所在的槽位并不归自己管理,这时它会向客户端发送一个特殊的跳转指令携带目标操作的节点地址,告诉客户端去连这个节点去获取数据。
数据一致性
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。
注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
数据迁移
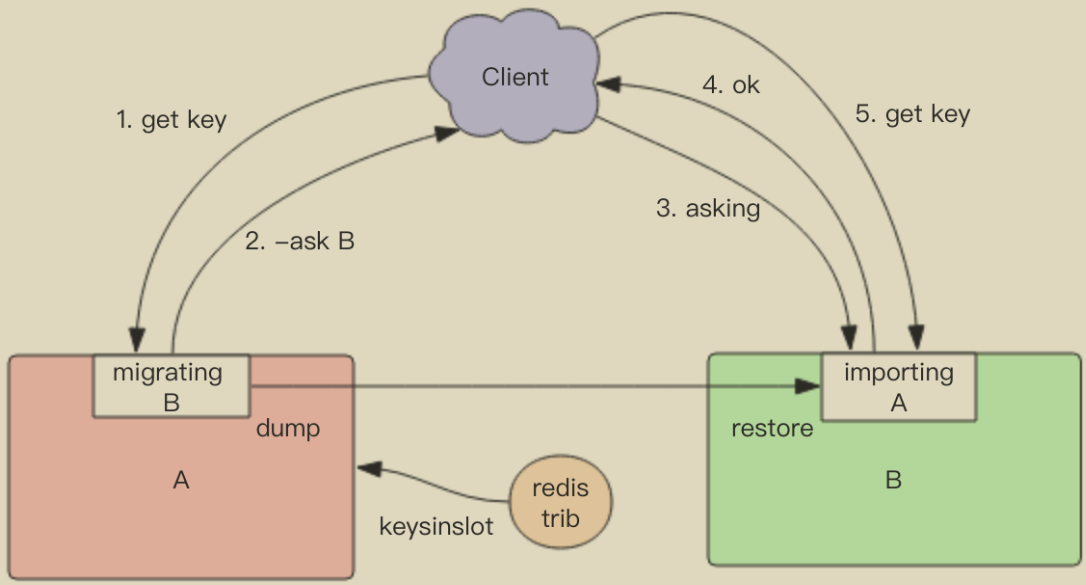
Redis Cluster 提供了工具 redis-trib 可以让运维人员手动调整槽位的分配情况,它使用 Ruby 语言进行开发,通过组合各种原生的 Redis Cluster 指令来实现。它不但提供了 UI 界面可以让我们方便的迁移,还提供了自动化平衡槽位工具,无需人工干预就可以均衡集群负载。
Redis 迁移的单位是槽,Redis 一个槽一个槽进行迁移,当一个槽正在迁移时,这个槽就处于中间过渡状态。这个槽在原节点的状态为 migrating,在目标节点的状态为 importing,表示数据正在从源流向目标。
迁移工具 redis-trib 首先会在源和目标节点设置好中间过渡状态,然后一次性获取源节点槽位的所有 key 列表(keysinslot 指令,可以部分获取),再挨个 key 进行迁移。每个 key 的迁移过程是以原节点作为目标节点的「客户端」,原节点对当前的 key 执行 dump 指令得到序列化内容,然后通过「客户端」向目标节点发送指令 restore 携带序列化的内容作为参数,目标节点再进行反序列化就可以将内容恢复到目标节点的内存中,然后返回「客户端」OK,原节点「客户端」收到后再把当前节点的 key 删除掉就完成了单个 key 迁移的整个过程。
从源节点获取内容 => 存到目标节点 => 从源节点删除内容。注意这里的迁移过程是同步的,在目标节点执行 restore 指令到原节点删除 key 之间,原
节点的主线程会处于阻塞状态,直到 key 被成功删除。
在迁移过程中,如果每个 key 的内容都很小,migrate 指令执行会很快,它就并不会影响客户端的正常访问。如果 key 的内容很大,因为 migrate 指令是阻塞指令会同时导致原节点和目标节点卡顿,影响集群的稳定型。所以在集群环境下业务逻辑要尽可能避免大 key 的产生。
容错
Redis Cluster 可以为每个主节点设置若干个从节点,单主节点故障时,集群会自动将其中某个从节点提升为主节点。如果某个主节点没有从节点,那么当它发生故障时,集群将完全处于不可用状态。不过 Redis 也提供了一个参数 cluster-require-full-coverage 可以允许部分节点故障,其它节点还可以继续提供对外访问。
网络抖动
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项 cluster-node-timeout,表示当某个节点持续 timeout 的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频繁切换 (数据的重新复制)。
可能下线 (PFAIL-Possibly Fail) 与确定下线 (Fail)
因为 Redis Cluster 是去中心化的,一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。所以集群还得经过一次协商的过程,只有当大多数节点都认定了某个节点失联了,集群才认为该节点需要进行主从切换来容错。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了 (PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。如果一个节点收到了某个节点失联的数量 (PFail Count) 已经达到了集群的大多数,就可以标记该节点为确定下线状态 (Fail),然后向整个集群广播,强迫其它节点也接收该节点已经下线的事实,并立即对该失联节点进行主从切换。
测试故障转移
# 查看集群的Master节点
redis-cli -p 7000 cluster nodes | grep master
# 模拟7000节点故障
redis-cli -p 7000 debug segfault
# 查看集群的Master节点(发现7003节点代替了7000节点)
redis-cli -p 7000 cluster nodes | grep master
RedisCluster 分片重哈希
# 集群重新分片
./redis-trib.rb reshard 127.0.0.1:7000
你想移动多少个槽( 从1 到 16384)? 100个槽位
哪个节点是用来接收槽位的? 节点id 7003
# 查看集群的Master节点(发现7003分配的槽位多了100)
redis-cli -p 7000 cluster nodes | grep master
./redis-trib.rb reshard 127.0.0.1:7000
# 添加一个新的Master节点 7006
./redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7000
你想移动多少个槽( 从1 到 16384)? 1000个槽位
哪个节点是用来接收槽位的? 节点id 7006
# 添加一个新的Slave节点
./redis-trib.rb add-node --slave 127.0.0.1:7007 127.0.0.1:7000
redis-cli -p 7000 cluster nodes #查看集群内所有节点信息
# 移除一个节点:第一个参数是任意一个节点的地址,第二个参数是你想要移除的节点地址。
./redis-trib.rb del-node 127.0.0.1:7000 `<node-id>`
# 移除从节点
* 移除从节点 直接移除成功
# 移除主节点【先确保节点里面没有slot】
* 使用同样的方法移除主节点,不过在移除主节点前,需要确保这个主节点是空的. 如果不是空的,需要将这个节点的数据重新分片到其他主节点上.
* 替代移除主节点的方法是手动执行故障恢复,被移除的主节点会作为一个从节点存在,不过这种情况下不会减少集群节点的数量,也需要重新分片数据.
SpringBoot 整合 RedisCluster
大多数用户可能会使用 RedisTemplate 它及其相应的包 org.springframework.data.redis.core- 由于其丰富的功能集,该模板实际上是 Redis 模块的中心类。该模板为 Redis 交互提供了高级抽象。虽然 RedisConnection 提供了接受和返回二进制值(byte 数组)的低级方法,但模板负责序列化和连接管理,使用户无需处理这些细节。
引入 spring-data-redis pom 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
引入 redistemplate
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.serializer.*;
import javax.annotation.Resource;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableCaching
public class RedisConfig {
// @Bean
// public RedisTemplate<String,String> redisTemplate(RedisConnectionFactory factory){
// RedisTemplate<String,String> redisTemplate = new RedisTemplate<>();
// redisTemplate.setConnectionFactory(factory);
// return redisTemplate;
// }
@Bean//RedisTemplate
public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory factory){
RedisTemplate<String, String> redisTemplate = new RedisTemplate<String,String>();
redisTemplate.setConnectionFactory(factory);
// 使用Jackson2JsonRedisSerialize 替换默认序列化
/**Jackson序列化 json占用的内存最小 */
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
/**Jdk序列化 JdkSerializationRedisSerializer是最高效的*/
// JdkSerializationRedisSerializer jdkSerializationRedisSerializer = new JdkSerializationRedisSerializer();
/**String序列化*/
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
/**将key value 进行stringRedisSerializer序列化*/
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setValueSerializer(stringRedisSerializer);
/**将HashKey HashValue 进行序列化*/
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
@Bean
public KeyGenerator simpleKeyGenerator() {
return (o, method, objects) -> {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(o.getClass().getSimpleName());
stringBuilder.append(".");
stringBuilder.append(method.getName());
stringBuilder.append("[");
for (Object obj : objects) {
stringBuilder.append(obj.toString());
}
stringBuilder.append("]");
return stringBuilder.toString();
};
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
return new RedisCacheManager(
RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory),
this.getRedisCacheConfigurationWithTtl(600), // 默认策略,未配置的 key 会使用这个
this.getRedisCacheConfigurationMap() // 指定 key 策略
);
}
private Map<String, RedisCacheConfiguration> getRedisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>();
redisCacheConfigurationMap.put("UserInfoList", this.getRedisCacheConfigurationWithTtl(100));
redisCacheConfigurationMap.put("UserInfoListAnother", this.getRedisCacheConfigurationWithTtl(18000));
return redisCacheConfigurationMap;
}
private RedisCacheConfiguration getRedisCacheConfigurationWithTtl(Integer seconds) {
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
redisCacheConfiguration = redisCacheConfiguration.serializeValuesWith(
RedisSerializationContext
.SerializationPair
.fromSerializer(jackson2JsonRedisSerializer)
).entryTtl(Duration.ofSeconds(seconds));
return redisCacheConfiguration;
}
}
配置 yml 配置文件
redis:
timeout: 6000ms
password:
# host: 192.168.31.220
# port: 6379
cluster:
max-redirects: 3 # 获取失败 最大重定向次数
nodes: 192.168.31.220:7000,192.168.31.220:7001,192.168.31.220:7002,192.168.31.220:7003,192.168.31.220:7004,192.168.31.220:7005
lettuce:
pool:
max-active: 1000 #连接池最大连接数(使用负值表示没有限制)
max-idle: 10 # 连接池中的最大空闲连接
min-idle: 5 # 连接池中的最小空闲连接
max-wait: -1 # 连接池最大阻塞等待时间(使用负值表示没有限制
使用 RedisTemplate
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
@RestController
public class RedisController {
@Resource
private RedisTemplate redisTemplate;
@Resource
private RedisService service;
@RequestMapping("/redis/setAndGet")
@ResponseBody
public String setAndgenValue(String name,String value){
redisTemplate.opsForValue().set(name,value);
return (String) redisTemplate.opsForValue().get(name);
}
@RequestMapping("/redis/setAndGet1")
@ResponseBody
public String setAndgenValueV2(String name,String value){
service.set(name,value);
return service.genValue(name).toString();
}
}
Redis Cluster 的适用场景与不足
显然 RedisCluster 在 4.0 之前会存在各种各样的问题,即便是在 4.0 之后也会存在网络性能问题(Gossip 协议)。
分片相关概念
- 水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中。 分片是一种基于数据库分成若干片段的传统概念扩容技术,它将数据库分割成多个碎片并将这些碎片放置在不同的服务器上。
- 垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。按照业务维度将不同数据放入不同的表。
Twitter 推特公司 twemproxy 服务端分片和客户端分片集群解决方案:
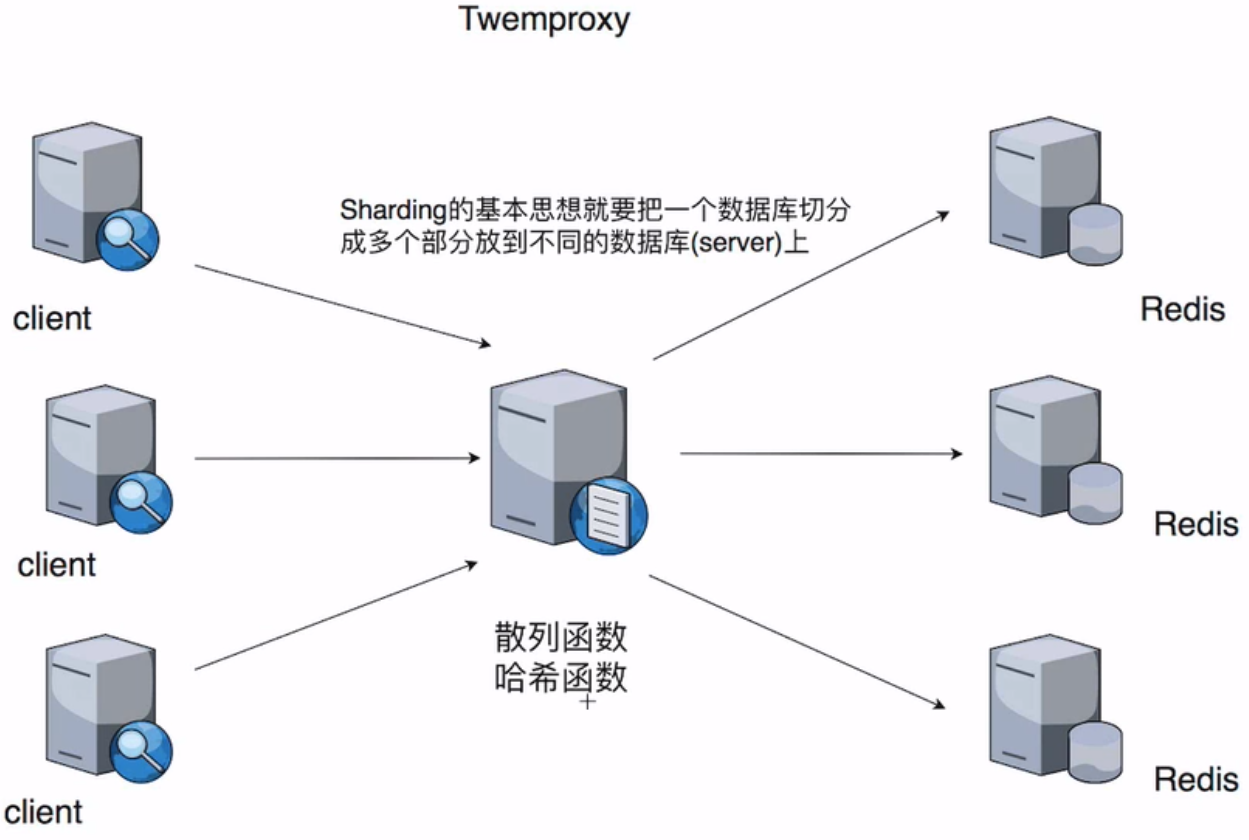
Redis3.0 之前实现集群方案
- 对 key 进行散列存储(CRC32 Hash)
* 客户端分片
* 服务器端分片
- 高可用:使基于主从复制的 Sentinel 模式。
Redis 的一致性 Hash 算法演进及优缺点分析
直接 Hash
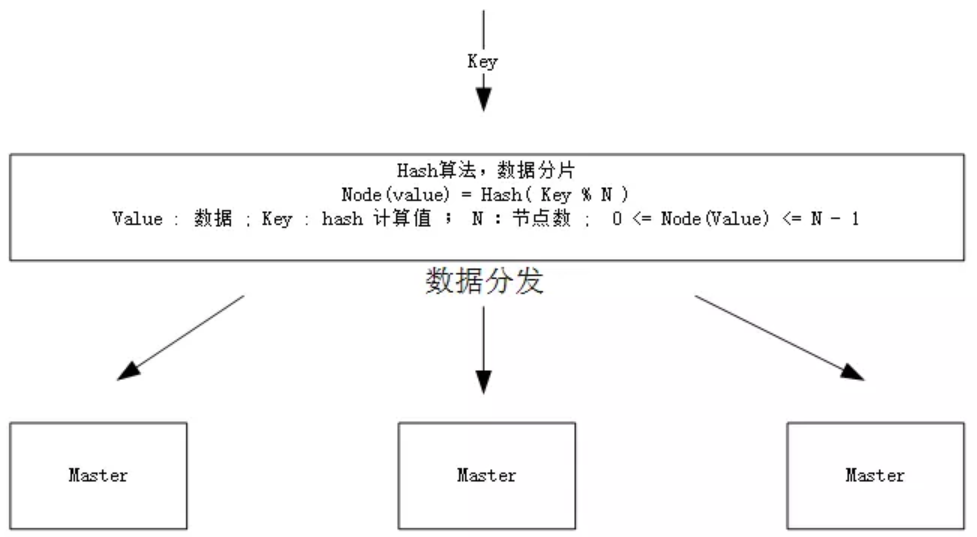
假设集群有 N 个 节点,一个请求的 key 的 Hash 值为 M,那么这个 key 对应的存储节点
K=M mod N
优点:简单易懂。
缺点:如果一个节点 L 宕机,那么新数据会落在 K=M mod (N-1)节点上,那么所有编号大于 L 的节点的数据都将错位,如果不做任何处理,那么这些缓存会全部无法命中。如果要做处理,只能将这些节点的所有旧缓存进行 rehash 操作。
一致性 Hash
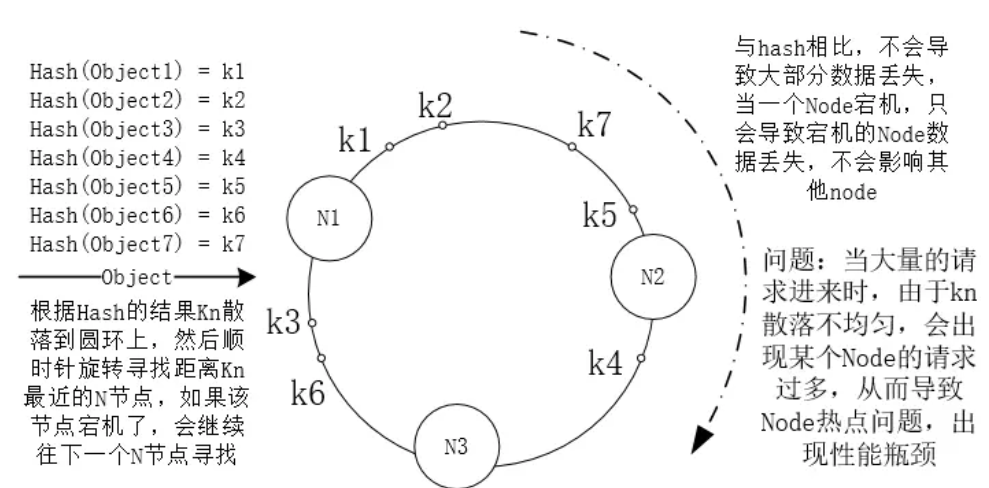
优点:宕机时只会导致宕机节点的缓存失效。
缺点:背锅的那个节点的压力瞬间变大,环上的节点在经过反复的接入和移出后其分布会不均匀,从而导致负载不均衡,形成缓存热点。
虚拟节点

- 增设虚拟节点:当物理机器数目为 A,虚拟节点为 B 的时候,实际 hash 环上节点个数为 A*B,将 A 节点分部为 A1,A2,A3;将 A1、A2、A3 平均分布在各个位置,使 A 服务的节点尽量均匀分配在各个角落。
- 每台服务器负载相对均衡:当某个节点挂了之后,其数据均衡的分布给相邻的顺时针后面的一个节点上面,故所有数据比之前所述一致性 hash 相对均衡。
优点:将节点与 Hash 算法解耦,而且通过交错分配虚拟节点的方式解决了负载不均衡导致的缓存热点问题。
缺点:虚拟节点只是为了让请求散落更均匀而存在,节点数量变化时虚拟节点数量也会变化,这种耦合限制的 hash 算法的进一步优化。比如在只有少量节点的集群中出现宕机时,其虚拟节点仍然会把负载传递给下一个相邻节点,无法把负载均匀拆分到所有节点,实现细粒度管理。
Hash Slot(Redis Cluster)
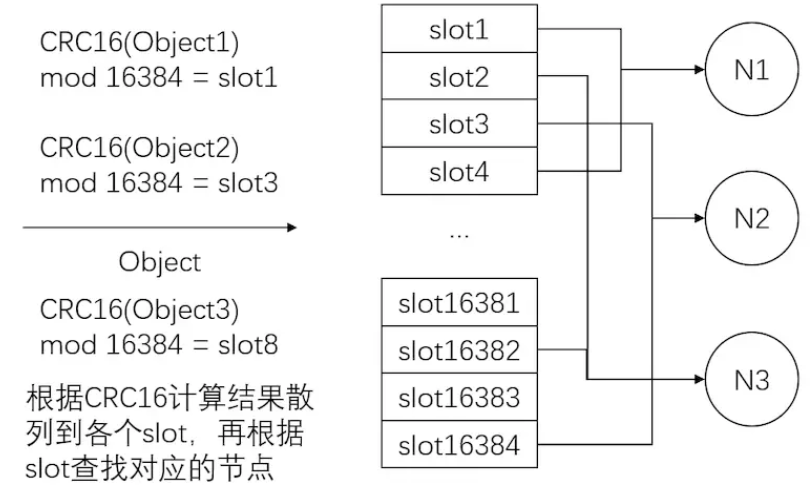
Redis cluster 拥有固定的 16384 个 slot (槽) ;这个槽是虚拟的,并不是真正存在。slot 被 分布到 各个 master 中,当 某个 key 映射到 某个 master 负责的槽时,就由对应的 master 为 key 提供服务
在 Redis cluster 中,只有 master 才拥有对 slot 的所有权,slave 只负责使用 slot,并没有所有权。
那么 Redis Cluster 又是如何知道哪些槽是由哪些节点负责的呢?Master 又是如何知道哪个槽是自己的呢?
位序列结构(节约存储空间)
每个 Master 节点都维护着一个位序列,为 16384 / 8 字节;Master 节点 通过 bit 来标识哪些槽自己是否拥有。比如对于编号为 1 的槽,Master 只要判断序列的第二位(索引从 0 开始)是不是为 1 即可。
集群同时维护着槽与集群节点的映射关系,由 16384 个长度的数组记录,槽编号为数组的下标,数组内容为集群节点,这样就可以很快地通过槽编号找到负责这个槽的节点。
Redis cluster 是通过什么样的方式进行分片存储的 key 与 slot 的映射算法公式如下:
HASH_SLOT=CRC16(key) mod 16384
Redis cluster 通过对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot,对于一批量数,如果想让批量数据都在同一个 slot,可以通过 hash tag 来实现。
Redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot 。
hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去(移动 hash slot 的成本是非常低的)。
优点:由于 Hash Slot 的数量多达 16384 个,所以每个集群节点都会分配到很多个 slot,当某个 master 宕机时,不会影响其他机器的数据,因为找的是 hash slot,从而实现细粒度的控制管理。比如加入新节点的时候可以从多个节点中抽取少量 slot,而移出节点后可以再把 slot 均匀分配给其他节点,让所有节点分摊缓存压力,这样既保证了负载的均匀分布,又保证了节点接入和移出的高效性。
客户端分片
客户端实现 hash 分片通过一致性 hash 算法来实现,对应的类是 jedis 的 ShardedJedisPool(一致性 hash 算法)。
客户端分片的主要特点:
- 分区逻辑由客户端实现
- 由客户端决定请求哪个节点
- 适用于用户对客户端的请求有完全的控制能力的场景
缺点:缩容和扩容比较难以控制。
服务器端分片
Twemproxy,也叫 nutcraker。是一个 twtter 开源的一个 Redis 和 memcache 快速/轻量级代理服务器; Twemproxy 是一个快速的单线程代理程序,支持 Memcached 和 Redis。Redis 代理中间件 twemproxy 是一种利用中间件做分片的技术。twemproxy 处于客户端和服务器的中间,将客户端发(Springboot 或服务)来的请求,进行一定的处理后(sharding),再转发给后端真正的 Redis 服务器。
Twemproxy 代理层作用
Twemproxy 通过引入一个代理层,可以将其后端的多台 Redis 或 Memcached 实例进行统一管理与分配,使应用程序只需要在 Twemproxy 上进行操作,而不用关心后面具体有多少个真实的 Redis 或 Memcached 存储。
Twemproxy 特性
- 支持失败节点自动删除
* 可以设置重新连接该节点的时间
* 可以设置连接多少次之后删除该节点
- 减少了客户端直接与服务器连接的连接数量
* 自动分片到后端多个redis实例上
- 多种哈希算法
* md5,crc16,crc32,crc32a,fnv1_64,fnv1a_64,fnv1_32,fnv1a_32,hsieh,murmur,jenkins
- 多种分片算法
* ketama(一致性hash算法的一种实现),modula,random