
Redis读写分离
读写分离的应用场景
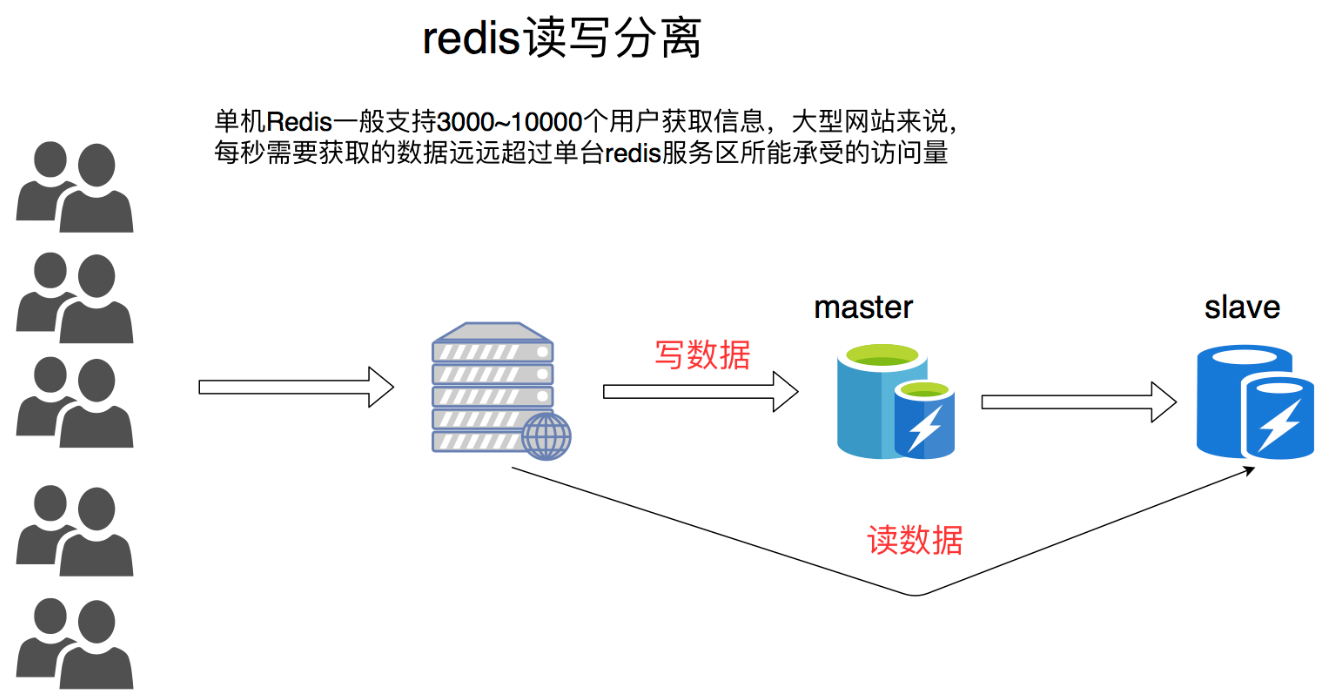
海量并发性能瓶颈处理,横向扩展,大幅度提升抗压能力。
Redis 的主从数据是异步同步的,所以分布式的 Redis 系统并不满足「一致性」要求。当客户端在 Redis 的主节点修改了数据后,立即返回,即使在主从网络断开的情况下,主节点依旧可以正常对外提供修改服务,所以 Redis 满足「可用性」。
运行一些额外的服务器,让它们与主服务器进行连接,然后将主服务器发送的数据副本并通过网络 进行准实时的更新(具体的更新速度取决于网络带宽)通过将读请求分散到不同的服务器上面进行处理, 用户可以从新添加的从服务器上获得额外的读查询处理能力。
Redis 已经发现了这个读写分离场景特别普遍,自身集成了读写分离供用户使用。我们只需在 Redis 的配置文件里面加上一条,【slaveof host port】语句
目前我们讲的 Redis 还只是主从方案,最终一致性,无故障转移功能,主 Master 节点宕机,则无法写入。
读写分离架构配置流程
# 创建目录
[root@localhost redis-replication]# mkdir /usr/local/redis-replication
# 新建两个目录
[root@localhost redis-replication]# cd /usr/local/redis-replication/
[root@localhost redis-replication]# mkdir 6379 6380
# 复制配置文件
[root@localhost redis-replication]# cp /test/redis-4.0.6/redis.conf /usr/local/redis-replication/6379/
[root@localhost redis-replication]# cp /test/redis-4.0.6/redis.conf /usr/local/redis-replication/6380/
# 修改配置文件 6379
[root@localhost 6379]# vim /usr/local/redis-replication/6379/redis.conf
bind 0.0.0.0
port 6379
logfile "6379.log"
dbfilename "dump-6379.rdb"
daemonize yes
rdbcompression yes
[root@localhost 6379]# /test/redis-4.0.6/src/redis-server /usr/local/redis-replication/6379/redis.conf
# 修改配置文件 6380
[root@localhost 6379]# vim /usr/local/redis-replication/6380/redis.conf
bind 0.0.0.0
port 6380
logfile "6380.log"
dbfilename "dump-6380.rdb"
daemonize yes
rdbcompression yes
slaveof 192.168.31.220 6379
[root@localhost 6379]# /test/redis-4.0.6/src/redis-server /usr/local/redis-replication/6380/redis.conf
# 查看进程
[root@localhost 6379]# ps -ef| grep redis
root 54093 1 0 10:56 ? 00:00:00 /test/redis-4.0.6/src/redis-server 0.0.0.0:6379
root 55430 1 0 11:01 ? 00:00:00 /test/redis-4.0.6/src/redis-server 0.0.0.0:6380
root 55448 26233 0 11:01 pts/1 00:00:00 grep --color=auto redis
# 登陆6379
[root@localhost 6379]# /test/redis-4.0.6/src/redis-cli -p 6379
127.0.0.1:6379> set name soulboy
OK
# 登陆6380
[root@localhost ~]# /test/redis-4.0.6/src/redis-cli -p 6380
127.0.0.1:6380> get name
"soulboy"
读写分离之数据同步原理
进行复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称作“数据库状态一致”。
* RDB 全量持久化
* AOF append only if 增量持久化
redis2.8 版本之前使用旧版复制功能 SYNC
SYNC 是一个非常耗费资源的操作
- 主服务器需要执行 BGSAVE 命令来生成 RDB 文件,这个生成操作会耗费主服务器大量的的 CPU、内存和磁盘读写资源
- 主服务器将 RDB 文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络带宽和流量,并对主服务器响应命令
- 请求的时间产生影响:接收到 RDB 文件的从服务器在载入文件的过程是阻塞的,无法处理命令请求
2.8 版本之后使用 PSYNC
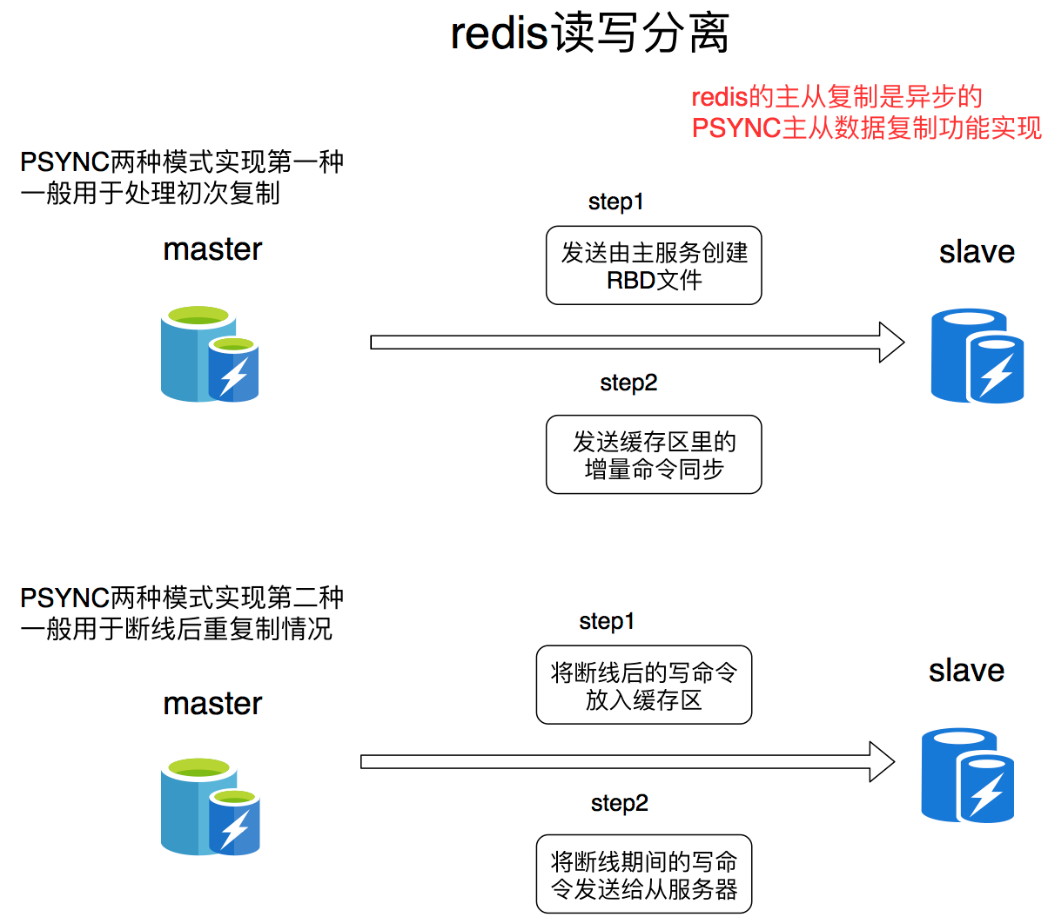
PSYNC 命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization1)两种模式。部分重同步功能由以下三个部分构成:
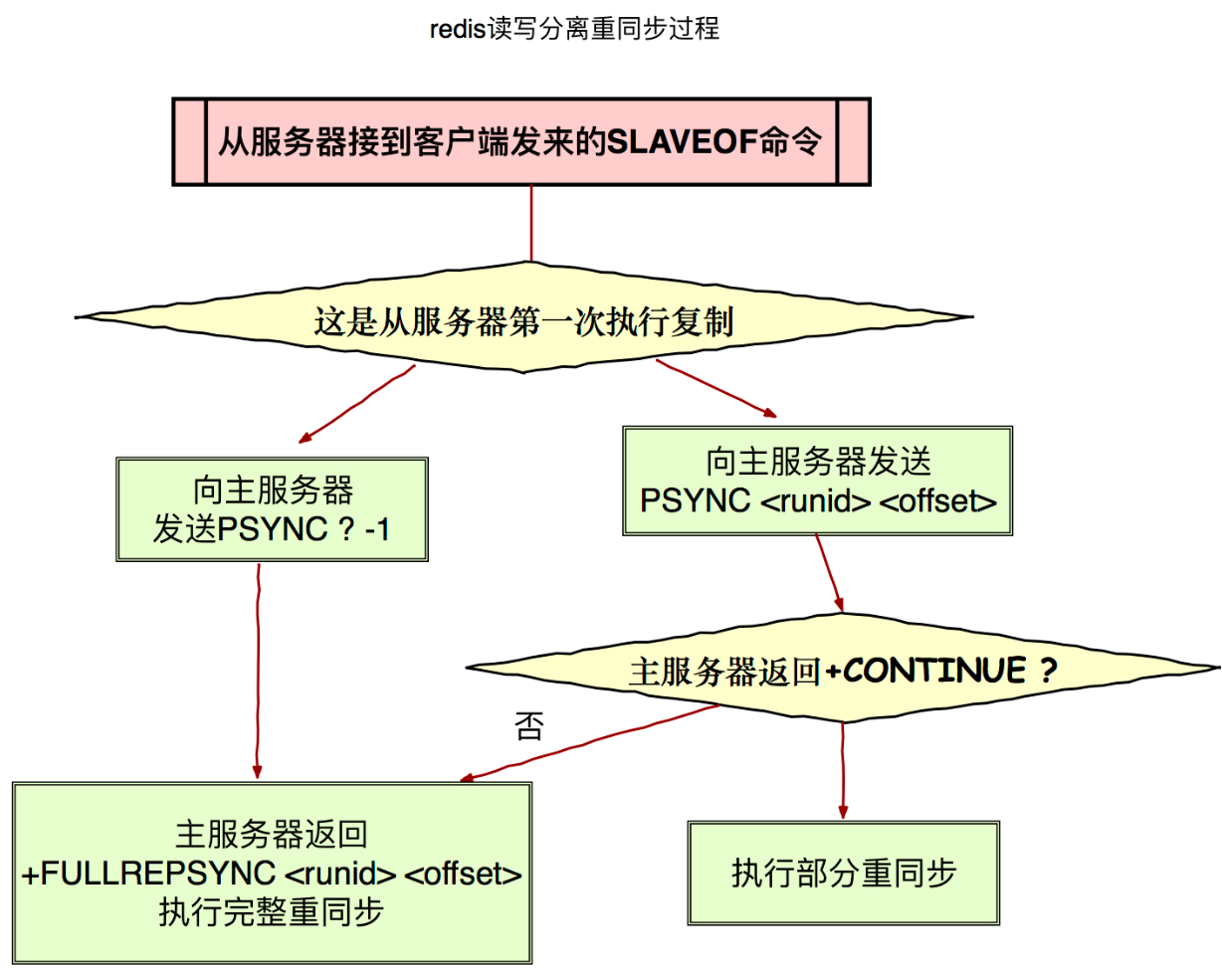
实现细节如下:
- 主服务的复制偏移量(replication offset)和从服务器的复制偏移量
- 主服务器的复制积压缓冲区(replication backlog),默认大小为 1M
- 服务器的运行 ID(run ID),用于存储服务器标识,如从服务器断线重新连接,取到主服务器的运行 ID 与重接后的主服务器运行 ID 进行对比,从而判断是执行部分重同步还是执行完整重同步。
分布式系统高可用
高可用 HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。单点是系统高可用的大敌,应该尽量在系统设计的过程中避免单点。
- 保证系统高可用,架构设计的核心准则是:冗余。
- 每次出现故障需要人工介入恢复势必会增加系统的不可服务实践,实现自动故障转移
- 重启服务,看服务是否每次都获取锁失败
分布式高可用经典架构环节分析
- 【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余来实现的。以 nginx 为例:有两台 nginx,一台对线上提供服务,另一台冗余以保证高可用, 常见的实践是 keepalived 存活探测
- 【反向代理层】到【Web 应用】的高可用,是通过站点层的冗余来实现的。假设反向代理层是 nginx,nginx.conf 里能够配置多个 Web 后端,并且 nginx 能够探测到多个后端的存活性。自动故障转移:当 web-server 挂了的时候,nginx 能够探测到,会自动的进行故障转移,将流量自动迁移到其他的 web-server,整个过程由 nginx 自动完成,对调用方是透明的。
- 【服务层】到【缓存层】的高可用,是通过缓存数据的冗余来实现的。 Redis 天然支持主从同步,Redis 官方也有 sentinel 哨兵机制,来做 Redis 的存活性检测。
- 【服务层】到【数据库层】的高可用,数据库层用“主从同步,读写分离”架构,所以数据库层的高可用,又分为“读库高可用”与“写库高可用”两类。读库采用冗余的方式实现高可用,写库采用 keepalived 存活探测 binlog 进行同步。