Prometheus
项目上线后如何保障业务的稳定性运行
-
高可用架构设计
- 采用分布式架构和容灾设计,确保系统的冗余与可恢复能力
- 包括多机房部署、多副本部署、负载均衡、热备份等策略,以应对单点故障和海量并发请求。
-
服务容错与降级
- 在面对故障或异常情况时,通过设计合适的容错机制和降级策略来保证核心业务的稳定进行
- 例如,对于关键服务,可以使用熔断器、限流器等技术来避免级联故障和请求雪崩。
-
自动化运维和发布
- 制定自动化的运维流程,包括自动化的部署、回滚、灰度发布等,减少人工操作引起的错误和风险。
- 同时,建立持续集成与持续交付(CI/CD)流程,确保代码的质量和稳定性
-
安全保障和漏洞修复
- 建立健全的安全策略和防护措施,保障系统和数据的安全。
- 同时及时修复系统中的漏洞和安全问题,避免被攻击者利用导致系统瘫痪或用户数据泄漏。
-
备份与恢复
- 定期进行系统数据的备份,并建立灾难恢复机制,备份可以包括系统配置、数据库、日志等关键数据
- 在系统发生故障时,能够及时将数据恢复到最新的可用状态。
如何发现业务的不稳定运行
互联网公司需要在开发、测试、发布、运维等不同阶段对产品进行监控,以便及时发现问题并采取相应措施
-
最终的核心:异常监控与预警
- 建立完善的监控系统,通过监控关键指标(如CPU、内存、带宽等)来实时感知系统的健康状态
- 同时设置预警规则,一旦异常发生,结合自动化运维及时通知相关人员并采取相应的应急措施。
- 比如
- 网络故障或稳定性问题
- 由于网络故障、硬件故障或配置错误等原因,可能会导致访问不稳定或宕机,进而影响用户的体验。
- 性能瓶颈和延迟
- 当用户访问量增加时,可能会对服务器产生超过负荷或达到带宽上限的压力,导致网页或其他平台响应速度变慢,影响用户体验和满意度。
- 数据安全性问题
- 不法分子可能通过攻击防火墙、病毒、恶意软件等途径获取数据或进行恶意操作,在一定程度上破坏了数据的安全性
- 网络故障或稳定性问题
-
公司建设监控和告警系统的意义
- 提前预知和识别问题
- 监控和告警系统可以帮助我们实时获取系统的运行数据和指标,
- 通过对关键指标的监控和分析,可以提前预知系统可能出现的问题,如性能下降、异常错误、服务不可用等。
- 通过告警及时发现问题,可以提高问题识别的速度和准确性,便于及时采取相应的措施来修复问题。
- 提高故障响应和处理效率
- 及时发现和处理故障可以减少系统的停机时间,避免影响用户体验和业务运行。
- 配置监控和告警系统可以帮助运维团队更快速地响应和解决问题,减少故障的恢复时间,减少业务损失。
- 优化系统性能和资源利用
- 监控和告警系统可以实时监测系统的性能和资源利用情况,如CPU、内存、磁盘、网络等。
- 通过对系统的性能指标进行监控和分析,可以帮助我们了解系统的负载情况和瓶颈
- 及时进行性能优化和资源扩展,以提高系统的稳定性和可扩展性。
- 安全风险的监测和应对
- 监控和告警系统还可以对系统的安全风险进行实时监测和预警。通过对异常访问、漏洞攻击、异常登录等进行监控和分析
- 可以帮助及时发现和应对潜在的安全风险,并保护系统和数据的安全。
- 提前预知和识别问题
监控系统常见的架构模式和主流系统对比
- Pull模式
- 优点
- 可以根据需要定时获取数据,避免数据的多余传输,节约网络带宽和存储空间。
- 可以根据需要通过请求的方式,选定性地获取部分数据。
- 适用于对被监控对象的稳定性要求不高的场景
- Pull模式核心消耗在监控系统侧,应用侧的代价较低
- 缺点:
- 由于需要定时发送请求获取数据,对于需要实时响应的业务,Pull模式的数据传输速度难以达到。
- Pull模式需要能够处理推送事件的应用程序,因此需要有较高的成本和复杂性。
- 优点
- Push模式
- 优点
- 被监控对象可以主动推送数据,监控服务端不需要发送请求,因此避免了网络负载。
- 对于需要实时响应数据的业务,Push模式具有更高的传输效率和更佳的实时性。
- Push模式适用于稳定的网络环境,可以实现实时数据的快速传输
- 缺点:
- Push模式核心消耗在推送和Push Agent端,监控系统侧的消耗相比Pull要小
- 被监控对象需要主动发送数据,不适用于对被监控对象要求性能较高的场景,需要严格控制被监控对象的数据流量
- 优点
- 总结
- 公司内部的监控系统来说,应该同时具备Pull和Push的能力才是比较合适的
主流监控告警框架对比
-
- Zabbix(支持 pull/push 两种模式)
- 基于C语言开发, 是一种基于服务器-客户端体系结构开发的企业级监控软件,它允许监控各种网络服务,服务器资源和硬件
- 优点:
- 用户友好,易于部署和设置
- 具有插件式框架,可以灵活地满足不同的监控需求
- 提供了丰富的图形化监控数据
- 具有高扩展性,用户可以轻松添加自定义功能。
- 缺点:
- 功能强大,使用比较笨重,Zabbix的安装和部署需要更多的时间和资源
- 对于复杂的IT架构,Zabbix的配置难度较大,
- 响应时间不够实时,对于实时性要求较高的应用场景可能不够理想
- Open-Falcon(push模式)
- 是一种分布式、高性能的监控解决方案,它被用于大型的高可用性系统和广泛的云计算环境
- 优点:
- 轻量级,可以部署在物理机和虚拟机上,部署和配置足够简单
- 支持查询优化,支持多种数据源输入
- 具有简单和易于使用的图形化界面
- 缺点:
- 国内使用量较小,社区不够活跃
- 对于某些复杂的IT架构,Open-Falcon在准备和安装方面可能存在困难
- 针对不同需求经验丰富的开发人员需代码调整
- Prometheus(Pull模式)
- go语言开发, 是可扩展的开源监控系统,用于收集存储多维度的时间序列数据
- 支持PromQL查询语言和提供的图形化展示工具
- 可视化和告警这些功能交由Grafana和Alertmanager等第三方产品来实现,拓展性强
- 功能上的简洁,作为一个轻量级的后起之秀,在性能和展示方面优势比较明显,对容器监控支持的非常好
- 优点:
- 可扩展性强,支持水平扩展,满足大规模监控需求
- 支持灵活的查询和查询语言,提供了丰富的查询函数和操作符
- 可以从不同的数据源收集数据,支持多维度数据聚合
- 可以轻松集成Alertmanager实现告警
- 缺点
- 存储机制不够灵活,大规模数据的存储和处理存在压力
- 对运维工程师的技术水平要求较高
- Zabbix(支持 pull/push 两种模式)
-
监控系统选择建议
- 功能和扩展性
- 不同的监控系统在功能和扩展性上有所差异,根据具体业务需求选择合适的功能和可扩展性。
- 适应的场景
- 不同的监控系统适用于不同的场景,如云原生环境、微服务体系等,根据具体的环境和需求选择合适的监控系统。
- 学习和维护成本
- 不同的监控系统可能需要不同的学习和维护成本,根据团队的技术能力和资源状况选择合适的监控系统。
- 社区支持和生态系统
- 选择具有活跃的社区支持和丰富的生态系统的监控系统,可以获得更好的开发、运维和解决问题的支
- 功能和扩展性
官网
-
一个开源的系统监控和警报工具,多数Prometheus组件是Go语言写的
-
为用户提供可视化仪表板、警报、告警等功能,以帮助用户快速定位和解决问题
-
现在已经成为一个独立于企业级的开源项目和一个独立的基金会(Cloud Native Computing Foundation)的一部分
-
用途
- Kubernetes集群监控
- 使用Prometheus可以收集和监控Kubernetes集群的指标数据,例如CPU、内存、网络等。
- 使用Prometheus Operator部署Prometheus,然后通过Grafana可视化工具展示监控指标的仪表板
- 网络监控
- Prometheus可以监控网络的状态和性能,例如TCP连接数、网络延迟和带宽利用率等
- 使用Prometheus的Blackbox Exporter插件来执行网络探测,检查网络服务是否可用
- 应用程序性能监控
- 通过Prometheus的客户端库可以在应用程序中嵌入指标收集代码,并收集应用程序的性能指标数据
- 例如请求数、响应时间、错误率等,帮助开发人员监控应用程序的性能,并进行调试和优化
- 数据库监控
- 可以使用Prometheus的Exporter插件监控各种类型的数据库,例如MySQL、PostgreSQL、Redis和MongoDB
- Exporter可以将数据库的指标数据转换为Prometheus可以处理的格式,并将其发送到Prometheus进行监控和警报
- 服务器监控
- 使用Prometheus可以监控服务器的CPU、内存、磁盘和网络使用情况等指标,服务器上运行的各种服务的状态和性能
- 能够实时地存储和查询系统和服务的各种指标,如性能、CPU利用率、内存使用和请求计数等。
- Kubernetes集群监控
架构
- 什么是时序数据库
- 是一种特定类型的数据库,随时间流逝而不断产生的数据,主要用来存储时序数据
- 常见的有InfluxDB、Kdb+、Prometheus、Graphite、TSDB
- 主要分为时间戳(timestamp)、标签(tag)、存档(filed)三大部分,按照时间顺序记录数据
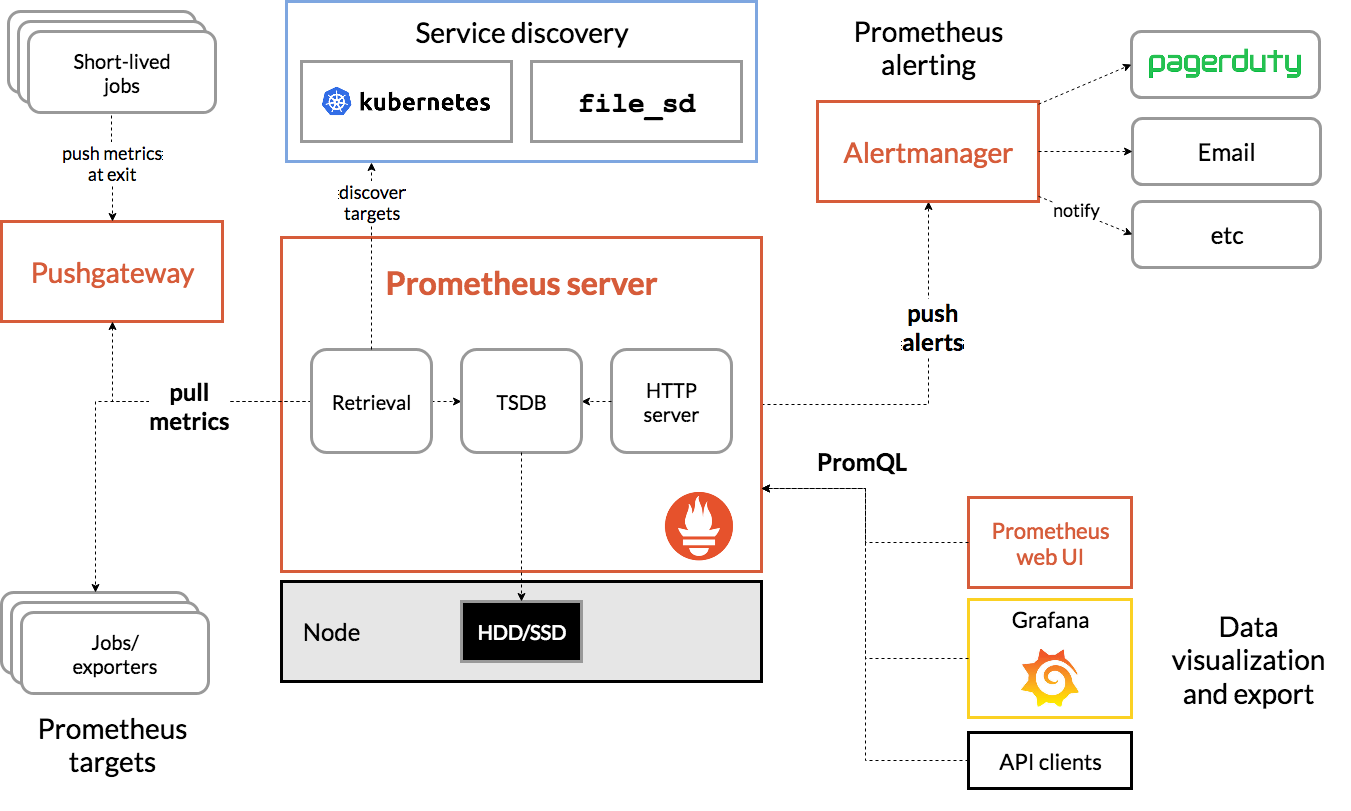
- 核心组成部分
- Prometheus server
- 核心组件,负责抓取、存储和查询指标数据,提供API以供访问
- Prometheus Server本身就是一个时序数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中
- 内置的UI界面,通过这个UI可以直接通过PromQL实现数据的查询以及可视化
- Exporter
- Prometheus插件或独立组件,负责抓取指定服务或系统的性能指标数据
- Prometheus原理是通过 HTTP 协议周期性抓取被监控组件的状态,输出这些被监控的组件的 Http 接口为 Exporter
- Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,将其公开为HTTP端点或指定的格式
- Prometheus server通过轮询或指定的抓取器从Exporter提供的Endpoint端点中提取数据
- Alertmanager
- 在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,就会产生一条告警
- Prometheus告警管理器组件,负责管理告警规则、通知和报警策略的设置,提供第一类和第二类警报的分类管理服务
- PushGateway
- Prometheus数据采集基于Pull模型进行设计,在网络环境必须要让Prometheus Server能够直接与Exporter进行通信
- 当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转
- 通过PushGateway将内部网络的监控数据主动Push到Gateway当中
- Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据
- Service Discovery
- 服务发现功能,动态发现待监控的Target,完成监控配置的重要组件
- Prometheus server
- 总结
- Prometheus服务直接通过目标拉取数据,或者间接地通过中间网关拉取数据
- 并通过一定规则进行清理和整理数据,把得到的结果存储到新的时间序列中
- 利用PromQL和其他API可视化地展示收集的数据
部署Prometheus Server
prometheus-2.43.0.linux-amd64.tar.gz
go1.17.6.linux-amd64.tar.gz
配置go环境变量(Prometheus使用go语言开发)
#解压
tar -zxvf go1.17.6.linux-amd64.tar.gz
#配置环境变量
echo "export PATH=$PATH:/usr/local/software/temp/go/bin" >> /etc/profile
#立刻生效
source /etc/profile
#测试 go是否安装成功
go version
安装Prometheus
#解压
tar -zxvf prometheus-2.43.0.linux-amd64.tar.gz
#重命名
mv prometheus-2.43.0.linux-amd64 prometheus
#进入目录启动
./prometheus --config.file=./prometheus.yml
# 动态更新(热更新:prometheus里面经常需要修改配置)
# 启动时在参数中加入******--web.enable-lifecycle****** (该参数默认关闭)
# 启动, &表示需要守护进程方式运行,不然退出终端则进程消失
./prometheus --config.file=./prometheus.yml --web.enable-lifecycle
#动态更新配置(不需要重启服务!!!)
curl -X POST http://localhost:9090/-/reload
#查看是否启动成功,默认端口9090
lsof -i:9090
# 关闭防火墙
systemctl stop firewalld.service
#访问 prometheus ,阿里云网络安全组开放端口
指标数据
http://192.168.10.20:9090/metrics
图界面
http://192.168.10.20:9090/
Prometheus操作面板和常见配置讲解
- Prometheus的目录结构
- console_libraries:用于存储用于在Prometheus控制台上显示的JavaScript库。
- consoles:用于存储用于在Prometheus控制台上显示的控制台文件,其中包括查询和图形定义。
- data:用于存储Prometheus的磁盘持久化数据。
- LICENSE:Prometheus的许可证文件。
- NOTICE:版权声明文件。
- prometheus:存储Prometheus二进制文件及其相关文件的目录。
- prometheus.yml:Prometheus的配置文件。
- promtool:Prometheus的命令行工具,用于检查配置文件是否正确以及生成表达式的值。
[root@localhost prometheus]# tree
.
├── console_libraries
│ ├── menu.lib
│ └── prom.lib
├── consoles
│ ├── index.html.example
│ ├── node-cpu.html
│ ├── node-disk.html
│ ├── node.html
│ ├── node-overview.html
│ ├── prometheus.html
│ └── prometheus-overview.html
├── data
│ ├── chunks_head
│ ├── lock
│ ├── queries.active
│ └── wal
│ ├── 00000000
│ └── 00000001
├── LICENSE
├── NOTICE
├── prometheus
├── prometheus.yml
└── promtool
配置文件介绍
#全局配置,默认,可以被覆盖
global:
scrape_interval: 15s #全局的抓取间隔
scrape_timeout: 10s #抓取超时时间
evaluation_interval: 15s #评估间隔
#告警配置
alerting:
alertmanagers: #告警管理器
- follow_redirects: true #是否启用重定向
enable_http2: true #是否启用HTTP2
scheme: http
timeout: 10s
api_version: v2 #指定Alertmanager的API版本,此处为v2
static_configs: #告诉Prometheus哪些目标是静态的(即不会更改),如果有多个目标,则可以在targets中指定多个地址。
- targets: []
#抓取配置
scrape_configs:
- job_name: prometheus #任务名称
honor_timestamps: true #指标的时间戳应该由服务器提供,而不是客户端在发送指标时提供的时间戳
scrape_interval: 15s #抓取任务的时间间隔,即每15秒抓取一次。
scrape_timeout: 10s #抓取任务的超时时间,单位为秒,即每个目标最多等待10秒钟
metrics_path: /metrics #抓取指标的路径
scheme: http #指定抓取时使用的协议,默认为http
follow_redirects: true #是否启用重定向。在此处启用
enable_http2: true #是否启用HTTP2
static_configs:
- targets:
- 120.24.7.58:9090 #目标配置,告诉Prometheus哪些目标需要抓取,如果有多个目标,则可以在targets中指定多个地址
#此处抓取了一个名为prometheus的任务,每隔15秒抓取一次120.24.7.58:9090上的/metrics路径,超时时间为10秒
监控分层和metric指标
Prometheus通过Pull方式采集指标数据,适用于分布式架构、云原生环境和微服务体系等场景
互联网公司监控和指标很多,按照顺序分层归类:系统层、应用层、业务层,这些Prometheus都可以完成
- 这些指标不是绝对的,应该根据企业的业务和系统选择合适的指标
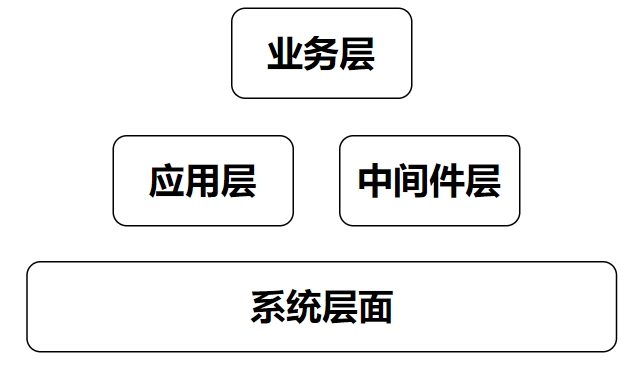
- 系统和网络层
- 主要关注底层基础设施的状态和事件,以确保服务器、网络、CPU和存储设备等运行正常,提供稳定的资源支持。
- 操心系统常见指标
- CPU利用率:服务器上CPU主要的核心使用率情况。
- 内存使用率:服务器内存使用情况,包括已使用、空闲等情况。
- 网络带宽利用率:服务器网络使用度,包括网卡、负载均衡、网络连接等的带宽使用情况。
- 硬盘I/O读写速度:磁盘读写速率。
- 硬盘容量:服务器硬盘容量使用情况,包括已使用、空闲等情况。
- ...
- 网络常见指标
- 带宽利用率:网络带宽利用率评估,包括上传和下载比率。
- 包丢失率:测量包在传输中丢失的数量和百分比。
- 网络流量:流经网络的实时数据量和数据流量。
- 网络错误率:网络传输中发生的错误数量和百分比。
- 连接数:网络连接总数。
- ...
- 应用层(业务应用程序、中间件应用程序等)
- 关注整体服务的质量和运行状态,能够及时预测系统运行瓶颈,保证产品的高效和用户体验
- 常见指标(java为例)
- 错误率:应用程序产生错误的请求占总数的百分比。
- 线程实例数:当前在应用程序中运行的线程实例数量。
- 堆内存使用率:应用程序中Java虚拟机(JVM)分配的内存占用的百分比。
- 平均延迟时间:从请求到响应开始的时间差。
- 垃圾回收时间:在JVM中收集不再使用的内存对象所需的时间。
- 响应代码:HTTP请求成功或失败代码。
- ...
- 业务层
- 重点关注业务运营的分析和结果,通过监控平台运营情况和各种配置,获取更多业务数据
- 及时发现行业发展趋势,指引业务方向,实现全方位监控、预测和干预
- 指标
- GMV销售额:项目特定时间内总的销售额。
- 日活、月活:日活跃用户数、月活跃用户数
- 客单价:平均每个订单的金额
- 支付成功率:成功支付订单和总订单的比率
- 订单量:每次交易中的订单数量。
- 购物车转化率:加入购物车商品与实际付款之间的比率。
- 点击率:网站广告点击率。
- ...
- 人工监控:客服和产品运营接收用户反馈(大厂里面的小部门挺多的)
- 技术人员一定要关注技术+业务 两个指标
- 技术指标(技术人员关注)
- 上述的系统+网络指标、应用指标
- 业务指标(产品和运营人员关注)
- 上述的业务指标就是
- 技术指标(技术人员关注)
Exporter:Node-Exporter
什么是Prometheus的Exporter
-
向Prometheus提供监控样本数据的程序都可以被称为一个Exporter
-
是一种用于将不同数据源的指标提供给Prometheus进行收集和监控的工具。
-
运行在应用程序、计算机、网络设备或者其他系统上的代码,它可以将系统的指标信息以一种标准格式公开
-
将指标数据公开为HTTP端点或者指定的格式(如Redis、JMX等),Prometheus然后可以通过轮询或指定的抓取器
-
总结
- Exporter是Prometheus的指标数据收集组件,负责从目标Jobs收集数据
- 并把收集到的数据转换为Prometheus支持的时序数据格式
- 只负责收集,并不向Server端发送数据,而是等待Prometheus Server 主动抓取
-
Prometheus社区以及其他团队开发了大量的Exporter,覆盖了许多不同类型的系统和服务
- Node Exporter、MySQL Exporter、Redis Exporter、MongoDB Exporter、Nginx Exporter...
-
使用方式
- 在主机上安装了一个 Exporter程序,该程序对外暴露了一个用于获取当前监控样本数据的HTTP访问地址
- Prometheus通过轮询的方式定时从这些Target中获取监控数据样本,并且存储在数据库当中
- 所有的Exporter程序都需要按照Prometheus的规范,返回监控的样本数据
案例实战 node_exporter
node-export 主要用来做Linux服务器监控,比如服务器的进程数、消耗了多少 CPU、内存,磁盘空间,iops等资源。
node_exporter-1.6.0.linux-amd64
#解压
tar -zxvf node_exporter-1.6.0.linux-amd64.tar.gz
#进到目录里面,启动
nohup ./node_exporter &
#确认端口
lsof -i:9100
# 访问exporter(成功!!!)
http://192.168.10.21:9100/metrics
# Prometheus服务器中添加被监控机器的配置(target的也可以写ip)
[root@localhost prometheus]# vim prometheus.yml
- job_name: 'soulboy-agent-1'
static_configs:
- targets: ['192.168.10.21:9100']
# 动态更新配置
[root@localhost prometheus]# curl -X POST http://192.168.10.20:9090/-/reload
Prometheus时序数据语法
所有的Exporter程序都需要按照Prometheus的规范,返回监控的样本数据
- 比如Node Exporter,当访问/metrics地址时会返回内容和本身Prometheus协议保持一致即可
- Prometheus协议格式主要由三个部分组成,Prometheus会对Exporter响应的内容逐行解析
- 样本的一般注释信息(HELP)
- 样本的类型注释信息(TYPE)
- 样本
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 6.884e-06
go_gc_duration_seconds{quantile="0.25"} 8.997e-06
go_gc_duration_seconds{quantile="0.5"} 9.849e-06
go_gc_duration_seconds{quantile="0.75"} 1.1542e-05
go_gc_duration_seconds{quantile="1"} 1.1542e-05
go_gc_duration_seconds_sum 3.7272e-05
go_gc_duration_seconds_count 4
-
Prometheus的时序数据模型:
-
指标(Metric)
- 一个指标是一个具有唯一名称的时间序列数据集合。
- 指标的完整名称由一个必需的名称和可选的标签键-值对组成,用冒号分隔
http_requests_total -
标签(Label)
- 标签用于区分相同指标的不同时间序列,一个时间序列可以有多个标签,标签由键-值对组成,通过逗号分隔
http_requests_total{method="GET", status="200"} -
样本(Sample)
- 样本是时间序列的数据点,包括时间戳和对应的值, 样本由指标和标签组成,通过空格分隔
http_requests_total{method="GET", status="200"} 500 1626866123000
-
-
案例一
- 业务系统,需要监控HTTP请求的总数,不同请求方法和状态码的请求次数,可以使用以下指标来描述这些数据
- 指标名称为
http_requests_total,表示HTTP请求的总数。 - 可以使用标签来区分不同请求方法和状态码。例如,使用
method标签表示请求方法,使用status标签表示状态码。 - 样本是具体的指标值和时间戳组成。例如,将
http_requests_total指标和标签组合成以下样本:
- 指标名称为
http_requests_total{method="GET", status="200"} 100 1626866123000 http_requests_total{method="POST", status="200"} 50 1626866123000 http_requests_total{method="GET", status="404"} 10 1626866123000- 表示在时间戳为1626866123000时
- GET方法的200状态码的请求总数为100次
- POST方法的200状态码的请求总数为50次
- GET方法的404状态码的请求总数为10次
- 使用这种时序数据模型,可以方便地进行数据查询和分析
- 业务系统,需要监控HTTP请求的总数,不同请求方法和状态码的请求次数,可以使用以下指标来描述这些数据
-
例如:可以通过以下PromQL查询语句统计不同请求方法的请求总数
sum(http_requests_total) by (method) -
案例二
- Linux服务器监控相关的CPU使用率,指标名称
node_cpu_seconds_total, 数据来源cat /proc/cpuinfo - 指标是counter类型的递增指标,指CPU 每种模式下所花费的时间
- 结合内置函数 统计CPU使用率
(1 -sum(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(rate(node_cpu_seconds_total[1m])) by (instance) )
- Linux服务器监控相关的CPU使用率,指标名称
统计指标
数值指标
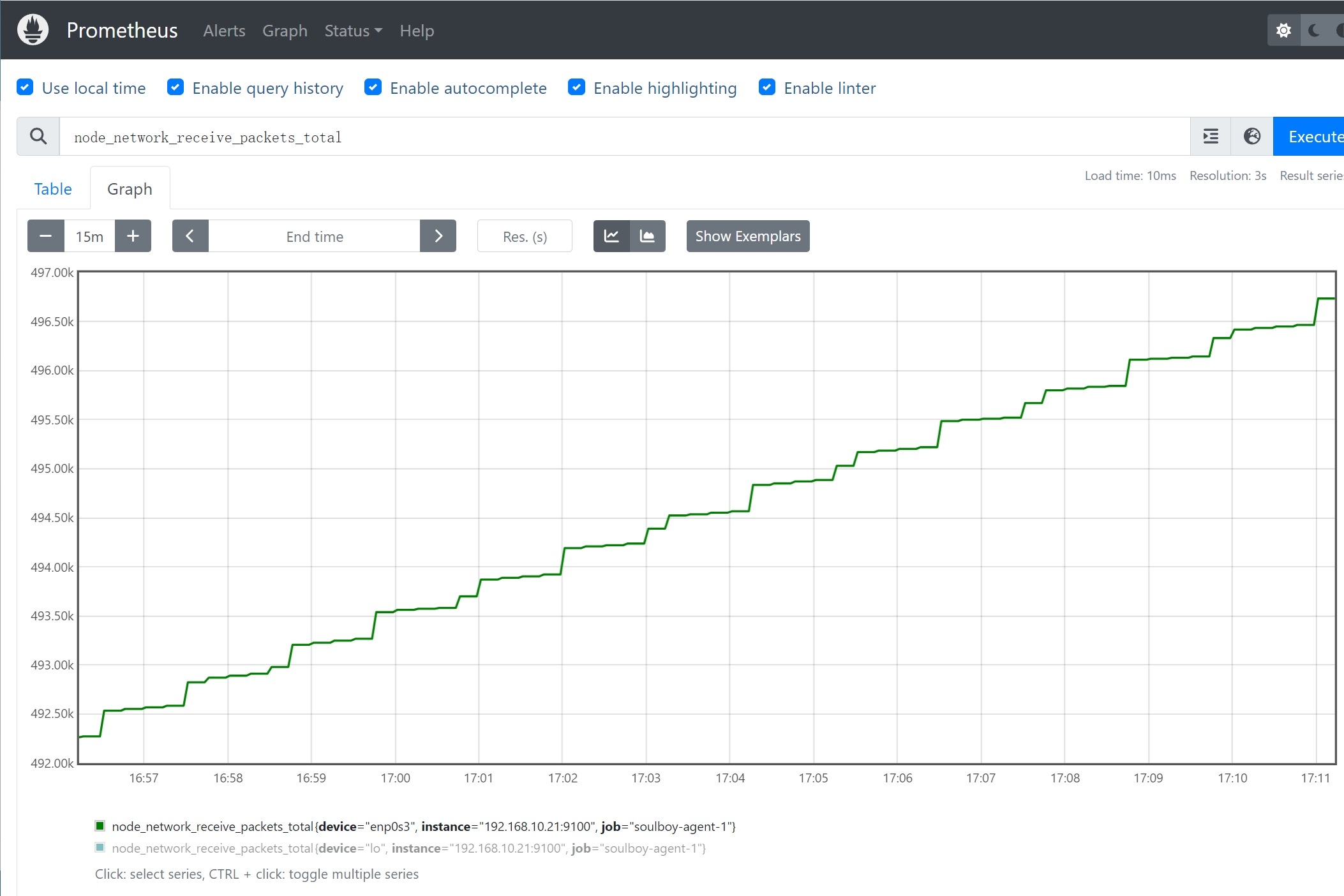
1、计数器 counter
- 计数器是一个递增的整数型指标,用于表示累计数量。
- 计数器在增长时,只能累加,不会减少。
- 一般用于统计请求次数、错误次数等场景。
案例:node_network_receive_packets_total表示网络接收的数据包总数。
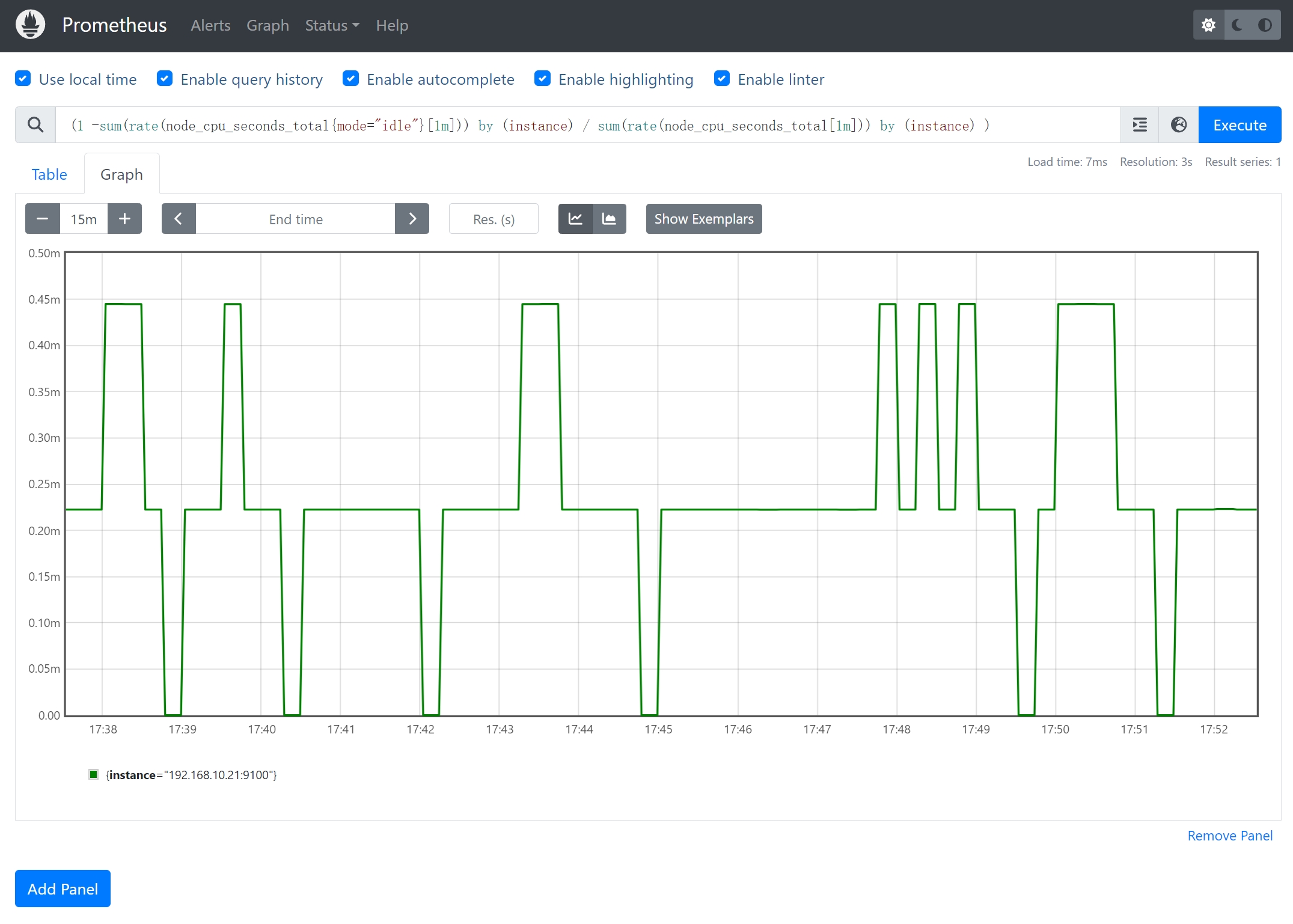
2、仪表盘 gauge
- 仪表盘是一个可变的数值指标,用于表示某个瞬时值
- 可变大,可变小。
- 仪表盘可以随着时间增加或减少,可以用于表示当前连接数、温度等持续变化的指标。
案例:统计CPU使用率
(1 -sum(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(rate(node_cpu_seconds_total[1m])) by (instance) )
统计指标
3、直方图 histogram
是一种直方图类型,可以观察到指标在各个不同的区间范围的分布情况,例如请求的延迟分布。
它会将这些事件按照不同的桶(bucket)进行分组,并收集每个桶内事件的数量,可以用于分析某个操作的响应时间。
案例:prometheus_http_request_duration_seconds_bucket{handler="/targets"}
- 用于查询路径为"/targets"相对应的 Prometheus HTTP 请求持续时间指标的直方图桶信息
- 记录HTTP请求的持续时间信息,并按照不同的时间区间(桶)进行分组。
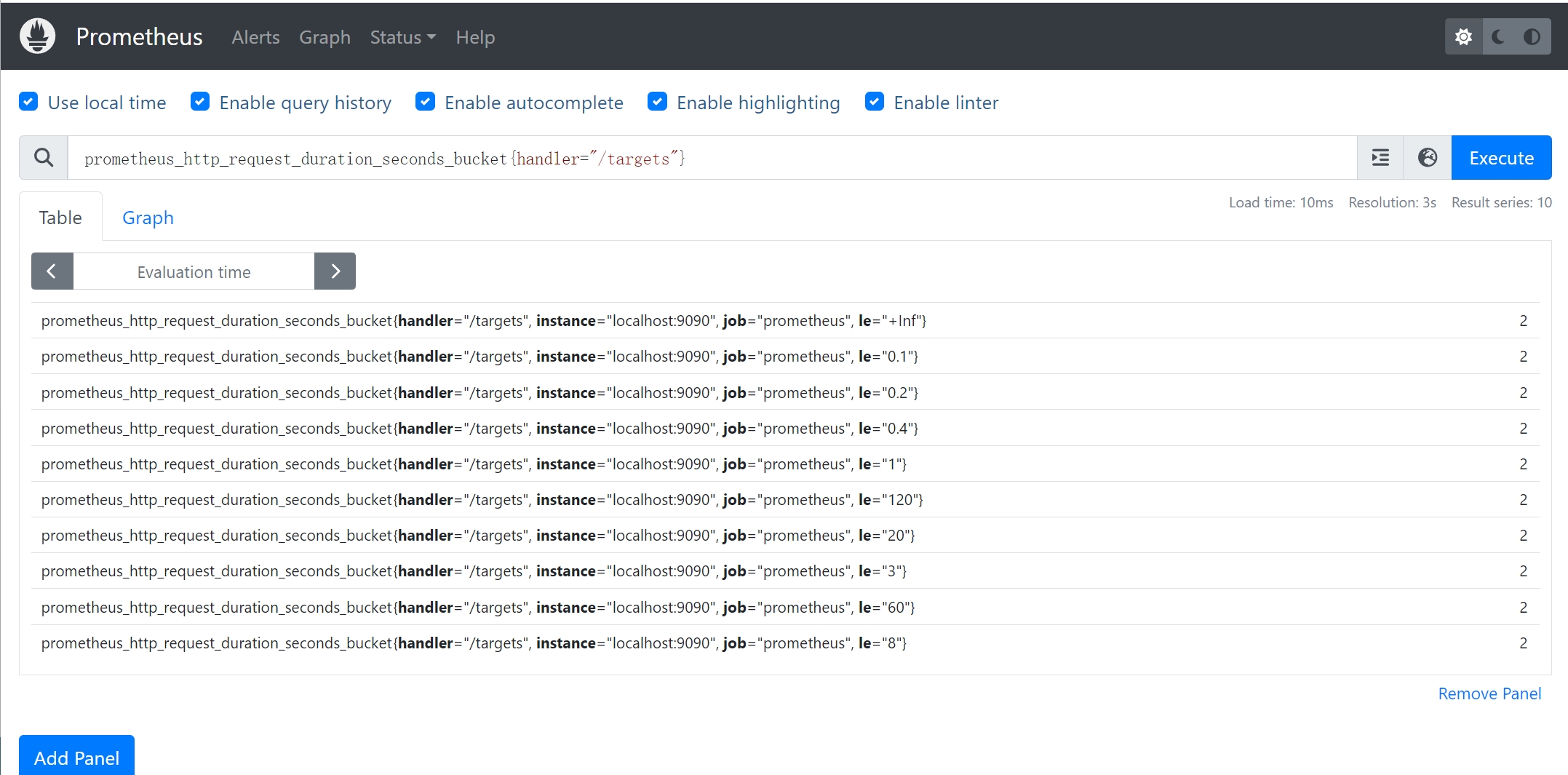
prometheus_http_request_duration_seconds_bucket{handler="/targets", le="0.1"} 2
prometheus_http_request_duration_seconds_bucket{handler="/targets", le="0.5"} 2
prometheus_http_request_duration_seconds_bucket{handler="/targets", le="1"} 2
- 在持续时间小于等于0.1秒的桶中有20个请求,在持续时间小于等于0.5秒的桶中有50个请求,以此类推。
### 注意 * 在le=“0.2”这个桶中是包含了 le=“0.1”这个桶的数据 * 如果想要拿到0.1毫秒到0.2毫秒的请求数量,可以通过两个桶相减得到 - 通过这样的查询,可以了解"/targets"处理程序路径下不同持续时间区间的HTTP请求的数量。
- 对于分析程序路径的请求延迟和性能非常有用
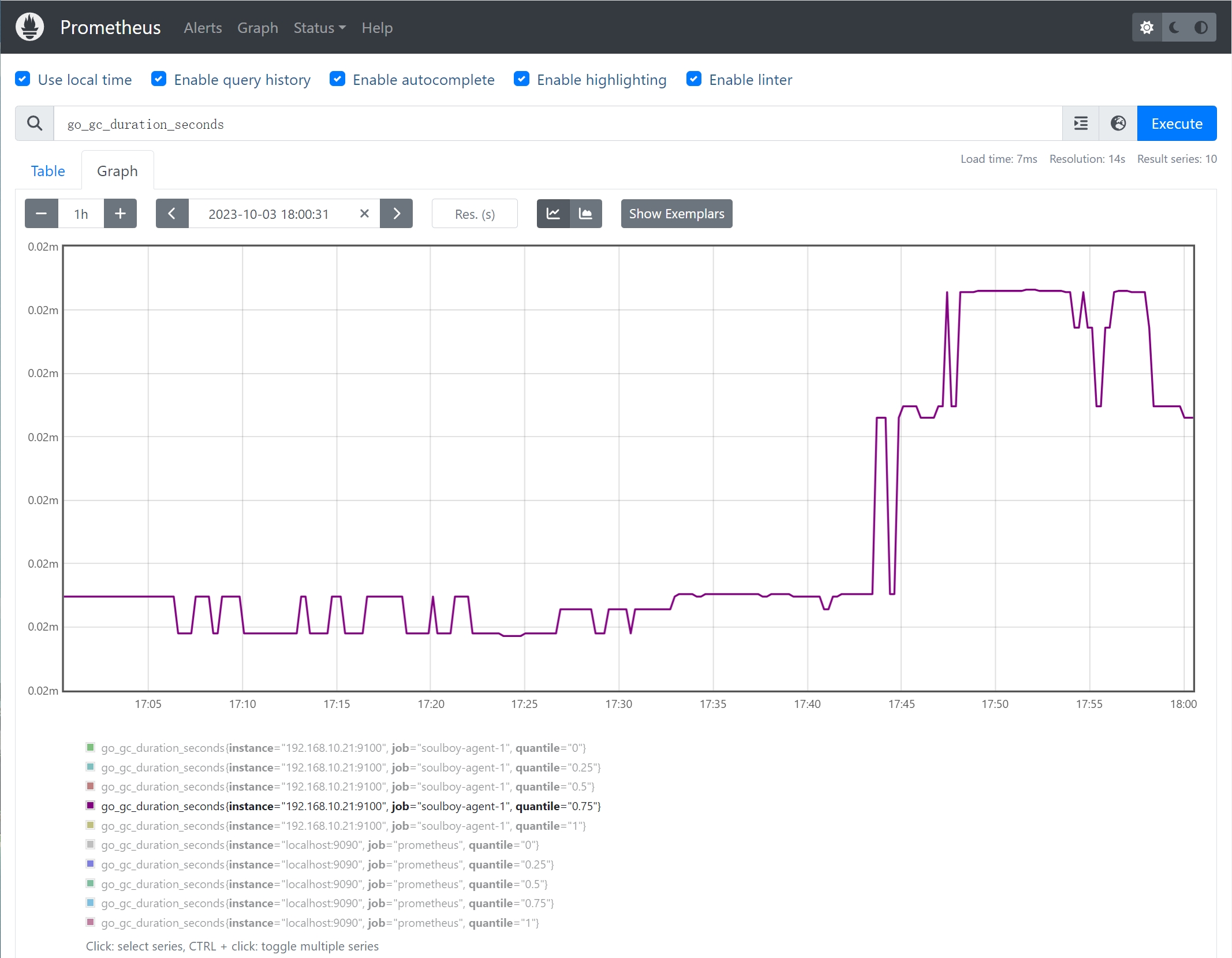
4、摘要summary
- 用于测量事件的分布情况,类似于直方图,和Histogram区别在于,Summary直接存储的就是百分位数
- 摘要适合于分析事件的分布和响应时间的百分比。
案例:
go_gc_duration_seconds,Go语言应用程序的指标,用于表示垃圾回收(Garbage Collection)的持续时间。
Prometheus监控Mysql8
### 部署mysql8
docker run \
-p 3307:3306 \
-e MYSQL_ROOT_PASSWORD=abc1024.pub \
--name mysql \
--restart=always \
-d mysql:8.0
### 配置mysql_exporter(对外暴露端口9104)监控MySQL,数据源格式:DATA_SOURCE_NAME="账号:密码@(ip:端口)
docker run -d --name mysql-exporter -p 9104:9104 -e DATA_SOURCE_NAME="root:abc1024.pub@(192.168.10.21:3307)/mysql" prom/mysqld-exporter:v0.14.0
### 查看exporter日志
[root@localhost ~]# docker logs -f mysql-exporter
### mysqld_exporter 的 metrics 默认端口 9104
http://192.168.10.21:9104/metrics
### Prometheus服务器中添加被监控机器的配置
[root@localhost ~]# vim /tmp/prometheus/prometheus.yml
- job_name: 'mysql-1'
static_configs:
- targets: ['192.168.10.21:9104']
### 动态更新配置
[root@localhost prometheus]# curl -X POST http://192.168.10.20:9090/-/reload
### 查看Web UI界面的target和configuration是否有对应的数据
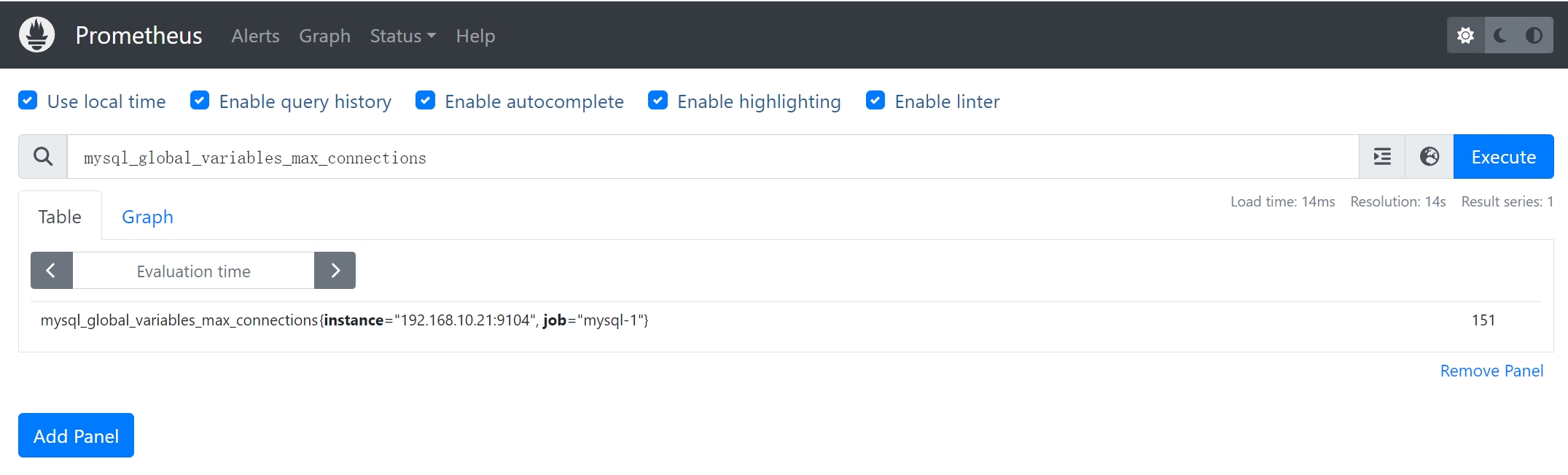
* 常见的关键指标
* `mysql_up`:表示 MySQL 数据库的可用性,如果值为1,则表示数据库连接正常;如果值为0,则表示数据库连接不可用。
* `mysql_global_status_threads_connected`:表示当前活动的连接数量。
* `mysql_global_status_threads_running`:表示当前正在执行的线程数量。
* `mysql_global_variables_max_connections`:表示 MySQL 数据库允许的最大连接数。
* `mysql_global_status_queries`:表示 MySQL 数据库执行的总查询次数。
* `mysql_global_status_slow_queries`:表示慢查询的数量。
* `mysql_global_status_innodb_buffer_pool_read_requests`:表示从 InnoDB 缓冲池中读取的请求数量。
* 注意
* 实际指标名称和标签可能会因使用的 MySQL 版本、Exporter 版本以及具体的配置变化而有所不同
* 只是一部分常见的关键指标,在实际使用中还有许多其他的指标进行监控分析。
* 通过这些关键指标,可以了解 MySQL 数据库的连接情况、查询性能、缓冲池状态等重要数据。
Prometheus监控Redis7
### 部署Redis7.X,并指定密码
docker run -itd --name redis -p 6379:6379 redis:7.0.8 --requirepass 123456
### 配置Redis-Exporter,指定相关redis服务端IP和密码
docker run -d --name redis_exporter -p 9121:9121 oliver006/redis_exporter --redis.addr redis://192.168.10.21:6379 --redis.password '123456'
### redis_exporter 的 metrics 默认端口 9121
http://192.168.10.21:9121/metrics
### Prometheus服务器中添加被监控机器的配置
[root@localhost ~]# vim /tmp/prometheus/prometheus.yml
- job_name: 'redis-1'
static_configs:
- targets: ['192.168.10.21:9121']
### 动态更新配置
[root@localhost prometheus]# curl -X POST http://192.168.10.20:9090/-/reload
### 查看Web UI界面的target和configuration是否有对应的数据
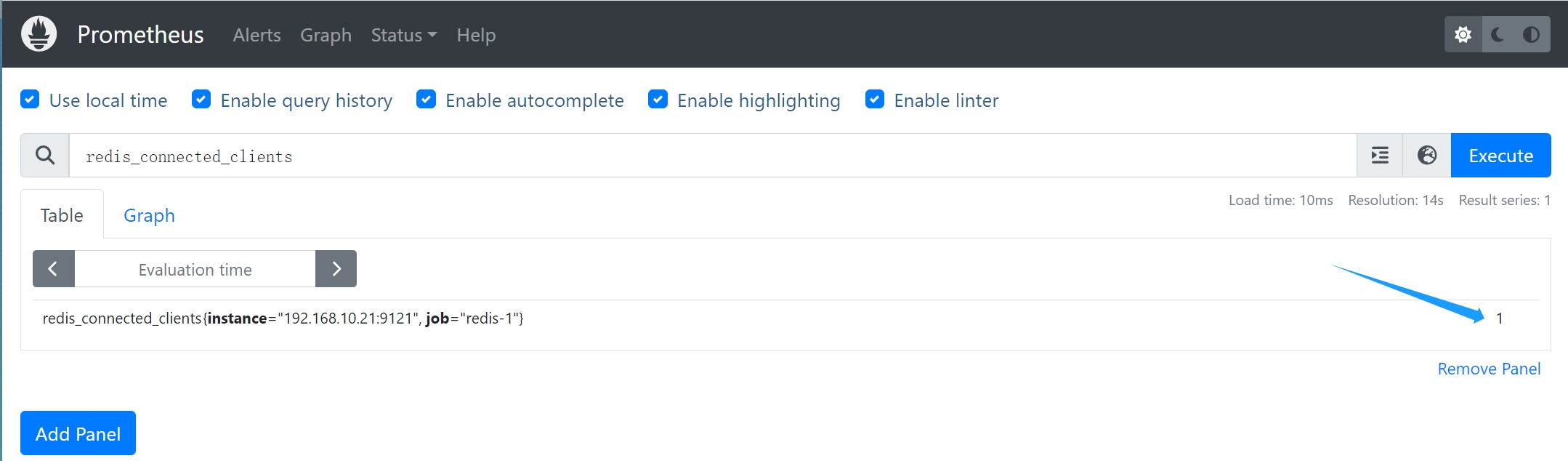
### 常见的 Redis Exporter 关键指标的示例
常见的 Redis Exporter 关键指标的示例
* `redis_up`:表示 Redis 服务器的可用性,如果值为1,则表示服务器连接正常;如果值为0,则表示服务器连接不可用。
* `redis_connected_clients`:表示当前连接到 Redis 服务器的客户端数量。
* `redis_memory_used_bytes`:表示 Redis 使用的内存总量。
* `redis_commands_processed_total`:表示 Redis 服务器处理的命令总数。
* `redis_keyspace_hits`:表示 Redis 服务器的键命中次数。
* `redis_keyspace_misses`:表示 Redis 服务器的键未命中次数。
* `redis_instance_info`:表示 Redis 服务器的各种信息,如服务器版本、机器信息、角色、端口等信息
Prometheus监控RabbitMQ
- RabbitMQ3.8.0之前版本,使用单独的下载插件prometheus_rabbitmq_exporter来向Prometheus公开指标
- RabbitMQ3.8.0版开始,RabbitMQ附带了内置的Prometheus&Grafana支持,但是默认没开启
### 部署rabbitmq
docker run -d --hostname rabbit_host1 --name rabbit -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=123456 -p 15672:15672 -p 5672:5672 -p 15692:15692 rabbitmq:3.8.9-management
参数说明
-d 以守护进程方式在后台运行
-p 15672:15672 management 界面管理访问端口
-p 5672:5672 amqp 访问端口
-p 15692:15692 Prometheus监控相关的端口
--name:指定容器名
--hostname 设定容器的主机名
-e 参数 RABBITMQ_DEFAULT_USER 用户名 RABBITMQ_DEFAULT_PASS 密码
### 进入容器内部开启监控端点
docker exec -it [rabbitmq container id] bin/sh
docker exec -it rabbit bin/sh
# 进入容器开启 Exporter
rabbitmq-plugins enable rabbitmq_prometheus
### Prometheus服务器中添加被监控机器的配置
[root@localhost ~]# vim /tmp/prometheus/prometheus.yml
- job_name: 'rabbitmq-1'
static_configs:
- targets: ['192.168.10.21:15692']
### 动态更新配置
[root@localhost prometheus]# curl -X POST http://192.168.10.20:9090/-/reload
### 查看Web UI界面的target和configuration是否有对应的数据
常见的关键指标
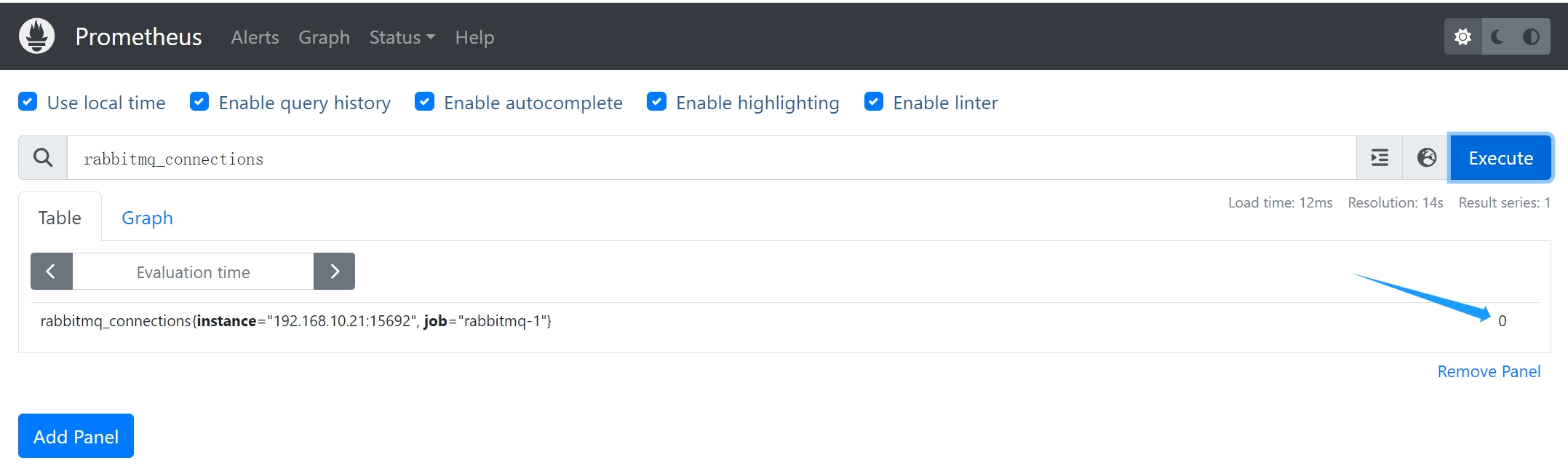
* `rabbitmq_queue_messages`: RabbitMQ队列中的消息数量。
* `rabbitmq_queue_messages_ready`: RabbitMQ队列中准备就绪的消息数量。
* `rabbitmq_connections`: RabbitMQ服务器的连接数量。
* `rabbitmq_queue_consumers`: RabbitMQ队列的消费者数量。
SpringBoot3监控Actuator
- Spring Boot Actuator 是 Spring Boot 提供的一个可选模块,用于在运行时监控和管理 Spring Boot 应用程序
- 通过 Actuator可以暴露应用程序的状态、统计信息、日志和其他有用的运行时信息
- 本地 JDK17安装(SpringBoot3.X要求JDK17),没相关环境的可以去Oracle官网安装下JDK17
- 项目开发,快速创建 **https://start.spring.io/
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- actuator -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
默认只暴露 health 端点,可以配置更多端点
http://localhost:8080/actuator
// 20231004164926
// http://localhost:8080/actuator
{
"_links": {
"self": {
"href": "http://localhost:8080/actuator",
"templated": false
},
"health": {
"href": "http://localhost:8080/actuator/health",
"templated": false
},
"health-path": {
"href": "http://localhost:8080/actuator/health/{*path}",
"templated": true
}
}
}
配置application.properties
#暴露指定端点
#management.endpoints.web.exposure.include=env,info,config,health
#暴露全部
management.endpoints.web.exposure.include=*
http://localhost:8080/actuator
http://localhost:8080/actuator/metrics
http://localhost:8080/actuator/metrics/jvm.buffer.memory.used
现有的Actuator格式并非Promethus支持的格式,所以需要加入相关Promethus支持的包统一格式
<!--整合prometheus-->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
会新增prometheus端点:http://localhost:8080/actuator/prometheus
# HELP jvm_memory_usage_after_gc_percent The percentage of long-lived heap pool used after the last GC event, in the range [0..1]
# TYPE jvm_memory_usage_after_gc_percent gauge
jvm_memory_usage_after_gc_percent{area="heap",pool="long-lived",} 0.0033393502235412598
# HELP executor_pool_max_threads The maximum allowed number of threads in the pool
# TYPE executor_pool_max_threads gauge
executor_pool_max_threads{name="applicationTaskExecutor",} 2.147483647E9
# HELP jvm_memory_max_bytes The maximum amount of memory in bytes that can be used for memory management
# TYPE jvm_memory_max_bytes gauge
jvm_memory_max_bytes{area="heap",id="G1 Survivor Space",} -1.0
jvm_memory_max_bytes{area="heap",id="G1 Old Gen",} 8.589934592E9
...
关键指标说明
指标的具体名称和标签可能会因SpringBoot版本、监控工具和配置而有所不同
jvm_memory_max_bytes: JVM各个区域的最大可用内存(以字节为单位)jvm_memory_used_bytes: JVM使用的内存量(以字节为单位)jvm_threads_states_threads: JVM线程状态的数量process_cpu_usage: 进程的CPU使用率。process_start_time_seconds: 进程启动的时间戳。http_server_requests_seconds: HTTP请求的响应时间。tomcat_sessions_active_current: 当前活动的Tomcat会话数量。system_cpu_usage: 系统的CPU使用率
Maven打成jar包
arch-web-0.0.1-SNAPSHOT.jar
### maven打包
PS D:\Project\arch-web> cd .\arch-web\
PS D:\Project\arch-web\arch-web> pwd
Path
----
D:\Project\arch-web\arch-web
PS D:\Project\arch-web\arch-web> mvn install
### 本地也可以进行测试(如果本地都启动不成功就没有必要上传)
PS D:\Project\arch-web\arch-web\target> cd D:\Project\arch-web\arch-web\target
PS D:\Project\arch-web\arch-web\target> java -jar .\arch-web-0.0.1-SNAPSHOT.jar
### jar包上传CentOS7,守护进程启动
[root@localhost software]# nohup java -jar arch-web-0.0.1-SNAPSHOT.jar &
### 查看日志
[root@localhost software]# tail nohup.out
2023-10-04T17:52:21.738+08:00 INFO 4586 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1105 ms
2023-10-04T17:52:22.323+08:00 INFO 4586 --- [ main] o.s.b.a.e.web.EndpointLinksResolver : Exposing 14 endpoint(s) beneath base path '/actuator'
2023-10-04T17:52:22.398+08:00 INFO 4586 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2023-10-04T17:52:22.434+08:00 INFO 4586 --- [ main] soulboy.pub.archweb.ArchWebApplication : Started ArchWebApplication in 2.402 seconds (process running for 2.739)
CentOS7部署JDK17(运行jar包)
### 部署JDK17
[root@localhost software]# mkdir /usr/local/software
[root@localhost software]# tar -zxvf jdk-17_linux-x64_bin.tar.gz
[root@localhost software]# mv jdk-17.0.7 /usr/local/software/jdk17
[root@localhost ~]# vim /etc/profile
JAVA_HOME=/usr/local/software/jdk17
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
#保存生效
[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version "17.0.7" 2023-04-18 LTS
Java(TM) SE Runtime Environment (build 17.0.7+8-LTS-224)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.7+8-LTS-224, mixed mode, sharing)
Prometheus整合配置
### 修改配置文件
[root@localhost ~]# vim /tmp/prometheus/prometheus.yml
- job_name: "springboot"
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['192.168.10.21:8080']
### 动态更新配置
[root@localhost prometheus]# curl -X POST http://192.168.10.20:9090/-/reload
### 访问springboot actuator
http://192.168.10.21:8080/actuator/prometheus
# HELP system_cpu_count The number of processors available to the Java virtual machine
# TYPE system_cpu_count gauge
system_cpu_count 2.0
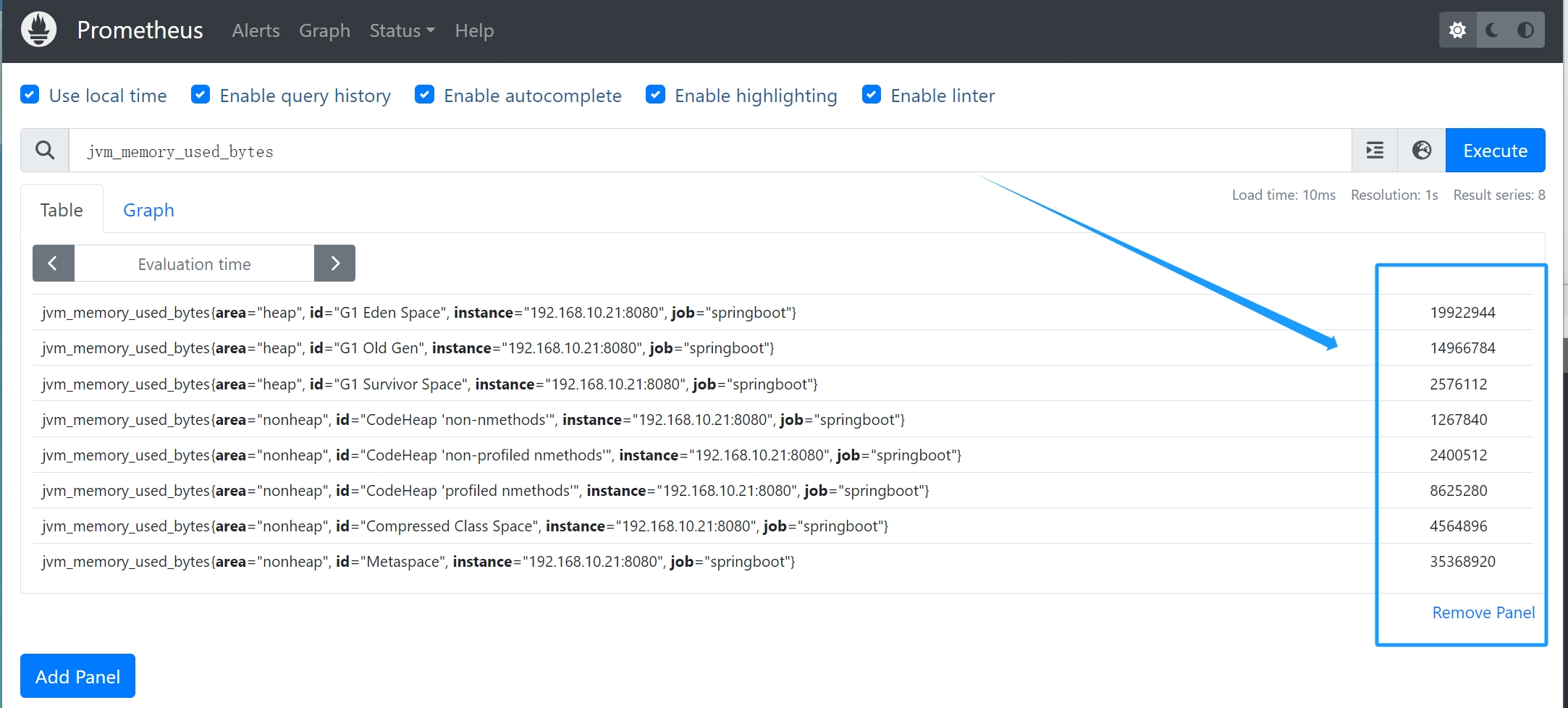
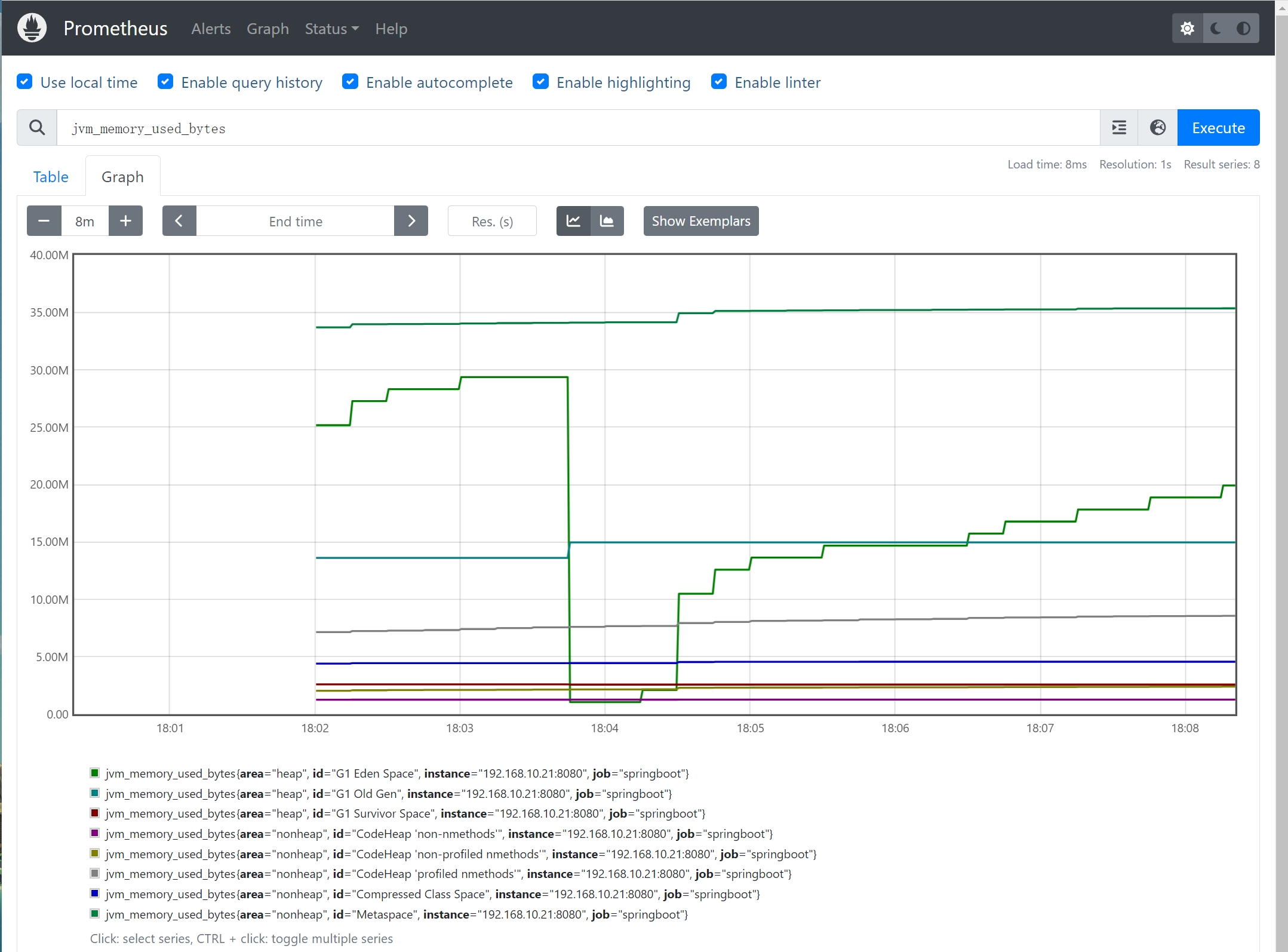
# HELP jvm_memory_used_bytes The amount of used memory
# TYPE jvm_memory_used_bytes gauge
jvm_memory_used_bytes{area="nonheap",id="CodeHeap 'profiled nmethods'",} 8090496.0
jvm_memory_used_bytes{area="heap",id="G1 Survivor Space",} 2576112.0
jvm_memory_used_bytes{area="heap",id="G1 Old Gen",} 1.4966784E7
jvm_memory_used_bytes{area="nonheap",id="Metaspace",} 3.5131496E7
jvm_memory_used_bytes{area="nonheap",id="CodeHeap 'non-nmethods'",} 1267840.0
jvm_memory_used_bytes{area="heap",id="G1 Eden Space",} 1.3631488E7
jvm_memory_used_bytes{area="nonheap",id="Compressed Class Space",} 4561584.0
jvm_memory_used_bytes{area="nonheap",id="CodeHeap 'non-profiled nmethods'",} 2313472.0
# HELP executor_completed_tasks_total The approximate total number of tasks that have completed execution
# TYPE executor_completed_tasks_total counter
executor_completed_tasks_total{name="applicationTaskExecutor",} 0.0
# HELP jvm_threads_daemon_threads The current number of live daemon threads
# TYPE jvm_threads_daemon_threads gauge
jvm_threads_daemon_threads 17.0
### prometheus web端查看
http://192.168.10.20:9090/

PromQL
什么是PromQL
- Prometheus提供了内置的数据查询语言PromQL,全称为Prometheus Query Language
- 是 Prometheus 自己开发的数据查询 DSL 语言,可以让用户实时选择和聚合时间序列数据
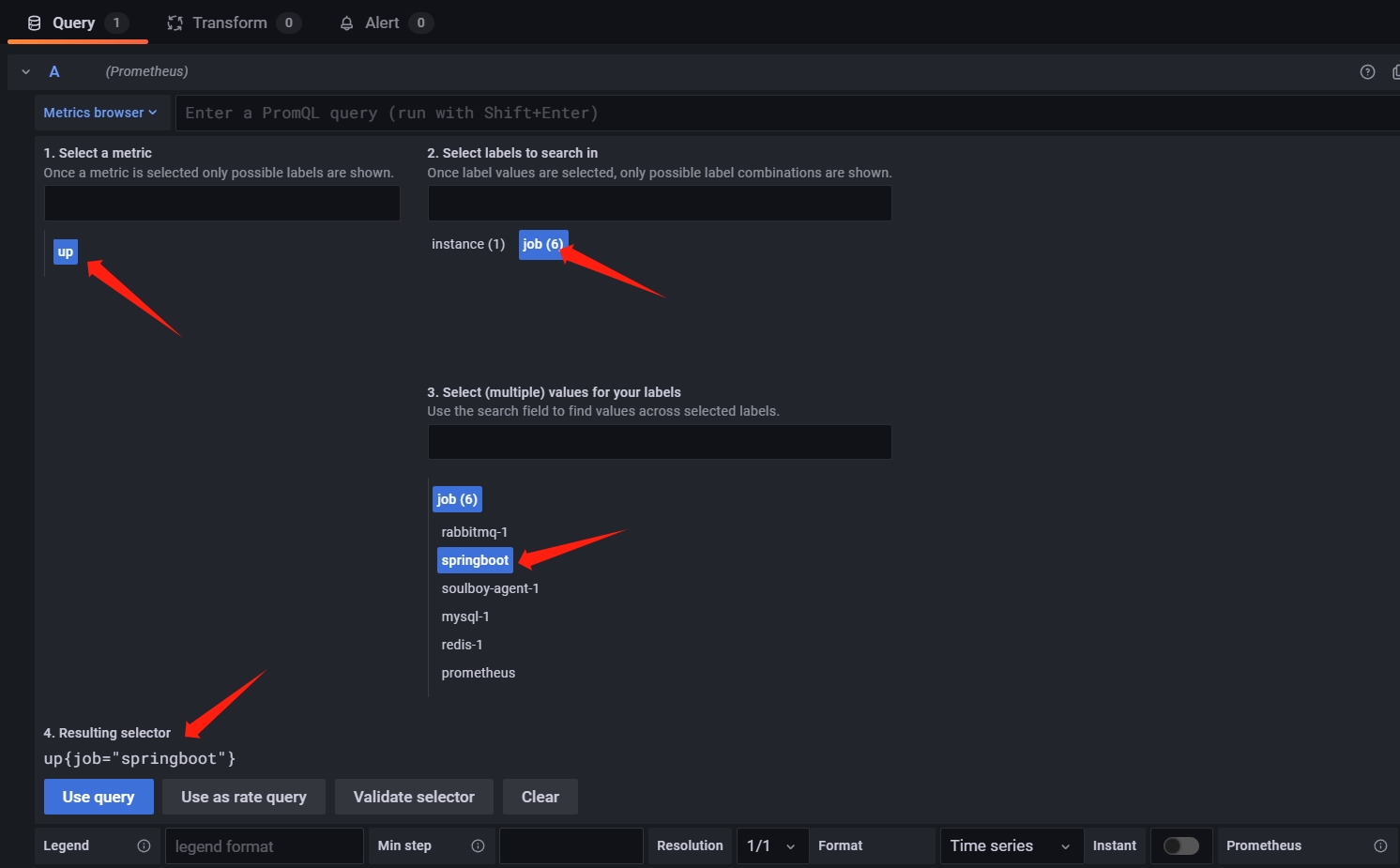
- PromQL是对指标(Metric)的查询/聚合/过滤的处理,Metric的语法格式
<metric name>{<label name>=<label value>, ...}
条件筛选
### 不带条件(两种写法都一样)
jvm_classes_loaded_classes
jvm_classes_loaded_classes{}
### 带条件
jvm_classes_loaded_classes{job="springboot"}
jvm_classes_loaded_classes{job!="springboot-test"}
不完全匹配
### 表示选择那些标签符合正则表达式定义的时间序列
label=~regx
### 进行排除
label!~regx
### 示例
jvm_classes_loaded_classes{job =~ "springboot|java|javaweb"}
时间范围选择器
### 支持多种时间单位
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
### 示例
# 过去五分钟的数据
up[5m]
# 一天之前的数据
up[1d]
数学运算符
- +(加法)、-(减法) 、*(乘法)、/(除法)、%(求余)、^(幂运算)
布尔运算符
- ==(相等)、!=(不相等)、>(大于)、<(小于)、>=(大于等于)、<=(小于等于)
### 筛选出请求次数超过 100 次的接口
prometheus_http_requests_total > 100
集合运算符
- and(并且-交集)、or(或者-并集)、unless(除非-补集)
聚合操作符
### 计算所有接口的请求数量总和
sum(prometheus_http_requests_total{})
### 匹配其中样本值为最小的时间序列
min(prometheus_http_requests_total{})
### 匹配其中样本值为最大的时间序列
max(prometheus_http_requests_total{})
### 求出所有样本的平均值
avg(prometheus_http_requests_total{})
### 请求数后 5 位的时序样本数据
bottomk (5,prometheus_http_requests_total{})
### 请求数前 5 位的时序样本数据
topk (5,prometheus_http_requests_total{})
### 计算一共有几条数据,和sum不一样,sum是对value进行求和
count (prometheus_http_requests_total{})
### 样本值升序排序
sort(prometheus_http_requests_total)
### 样本值倒序排序 (指定时间区间后,计算该指标在最早和最晚时间的值的差,即增长量)
sort_desc(prometheus_http_requests_total)
### 计算在过去1分钟内CPU使用时间的指标增长量
* 如果除以相关时间范围,则可以计算出增长率,和rate函数效果一样
* 单使用rate或者increase函数去计算样本的平均增长速率,容易陷入“长尾问题”,无法反应在时间窗口内样本数据的突发变化
increase(node_cpu_seconds_total[1m])
### 关键字(分组,类似 SQL 中的 group by)
* without 用于从计算结果中移除列出的标签,而保留其它标签
# 在prometheus_http_requests_total指标中,排除 instance,handler,job,来进行分组求和
sum(prometheus_http_requests_total{}) without (instance,handler,job)
* by 计算结果 中只保留列出的标签,其余标签则移除
# 在prometheus_http_requests_total指标中根据code来分组求和
sum(prometheus_http_requests_total{}) by (code)
### 指标值的变化速率:irate函数的图像峰值变化大,rate函数变化较为平缓
* rate函数的图像峰值变化大,rate函数变化较为平缓**
* 使用`irate`函数可以更精确地捕捉到短期内的变化,而`rate`函数则更适合用于观察长周期的趋势
* rate适合缓慢变化的计数器,使用了平均值,很容易把峰值削平,除非把时间间隔设置得足够小,就能够减弱这种效应
例如,计算过去5分钟内节点的网络接收字节数和传输字节数的变化速率
# rate适用于根据一定时间范围内的样本计算速率, 也就是我们常说的QPS,函数原型为:rate(vector range-vector)
rate只是算出来某个时间区间内的【平均速率】,没办法反映突发变化
假设在一分钟的时间区间里,前50秒的请求量都是0到10左右,但最后10秒请求量暴增到200以上,则不能很好反映变化
rate(node_network_receive_bytes_total[5m]) + rate(node_network_transmit_bytes_total[5m])
# irate函数以瞬间速率的方式返回时间序列的变化率(每秒),它适用于在一段时间内考虑单个样本的变化,会考虑时间范围内最近两个样本之间的变化
函数原型为:`irate(vector range-vector)`
irate(node_network_receive_bytes_total[5m]) + irate(node_network_transmit_bytes_total[5m])
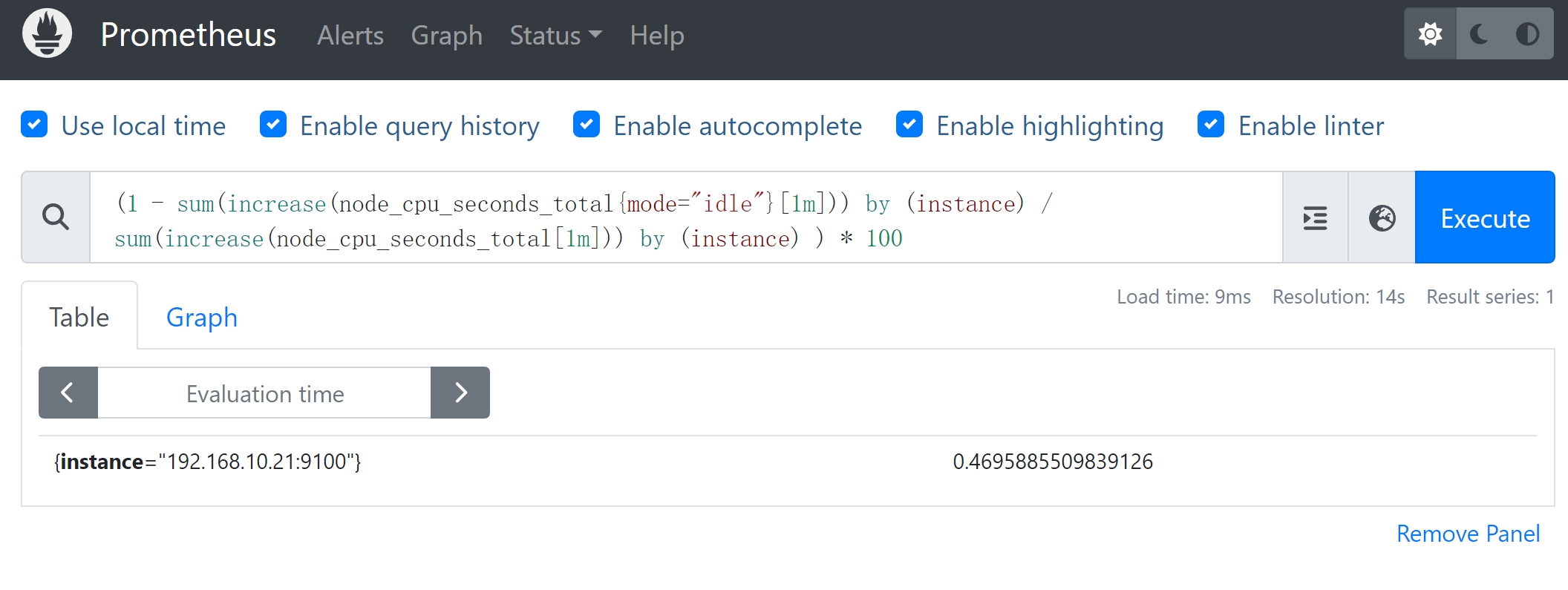
统计CPU使用率
需求
计算服务器的CPU的使用率(1分钟)
指标
node_cpu_seconds_total 用来统计 CPU 每种模式下所花费的时间,不加条件则是CPU使用时间总和
思路
- 计算CPU使用率,简单的说就是除idle状态之外的CPU时间除以CPU总时间
- CPU的使用率 = (所有非空闲状态CPU使用时间总和 )/(所有状态CPU时间总和)
- 用prometheus的计算思路就是:1- idle/total
#过滤出CPU空闲的时间
node_cpu_seconds_total{mode="idle"}
#统计idle状态时长
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
#统计总时长
#sum函数是将所有CPU核数时间相加,没有按照主机进行聚合,就需要引入 by (instance) 函数,即分组
#by (instance) 它会把sum求和到一起的数值按照指定方式进行拆分,instance代表的是机器名
#如果不写by (instance)的话就需要在{ }中写明需要哪个实例的数据
sum(increase(node_cpu_seconds_total[1m])) by (instance)
#计算出idle时长和总时长,CPU使用率的表达式
(1 - sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) ) * 100

Grafana
数据源广:
-
官网地址:https://grafana.com/
-
用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。
-
可视化
- 支持快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件
- 比如热图、折线图、图表等多种展示方式
- Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等。
- 支持混合数据源,在同一个图中混合不同的数据源,可以根据每个查询指定数据源,甚至适用于自定义数据源。
- 报警
- 支持可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时进行告警
- 避免混淆各个组件主要的作用概念
- Exporter 数据生产者,采集需要监控的数据
- Prometheus 普罗米修斯时序数据库,用来存储和查询的监控数据,从Exporter上拉取
- Grafana 可视化工具仪表盘
部署grafana
### docker部署grafana
docker run -d -p 3000:3000 --name=soulboy-grafana grafana/grafana:8.1.5
### URL admin 密码:admin
http://192.168.10.20:3000/login
配置数据源

-
用户
- Grafana 里面用户有三种角色 admin,editor,viewer
- admin 权限最高,可以执行任何操作,包括创建用户,新增 Datasource、DashBoard。
- editor 角色不可以创建用户,不可以新增 Datasource,可以创建 DashBoard。
- viewer 角色仅可以查看 DashBoard
-
组织
- 每个用户可以拥有多个 Organization,用户登录后可以在不同的 Organization 之间切换
- 不同的 Organization 之间完全不一样,包括 datasource,dashboard 等都不一样
- 创建一个 Organization 就相当于开了一个全新的视图,所有的 datasource,dashboard 等都要再重新开始创建
-
数据源 (Data Source )
- Grafana 支持多种不同的时序数据库数据源,对每种数据源提供不同的查询方法,而且能很好的支持每种数据源的特性
- 可以将多个数据源的数据合并到一个单独的仪表板上
-
仪表盘(Dashboard)
- 最重要 UI 界面 仪表盘,通过数据源定义好可视化的数据来源,Dashboard 来组织和管理数据可视化图表
- 仪表盘可以视为一组一个或多个面板组成的一个集合,来展示各种各样的面板。
-
面板 (Panel)
- Panel 在一个 Dashboard 中一个最基本的可视化单元为一个 Panel(面板)
- 通过 Panel 的 Query Editor(查询编辑器)为每一个 Panel 添加查询的数据源以及数据查询方式,每一个 Panel 都是独立的
-
探索 (Explore)
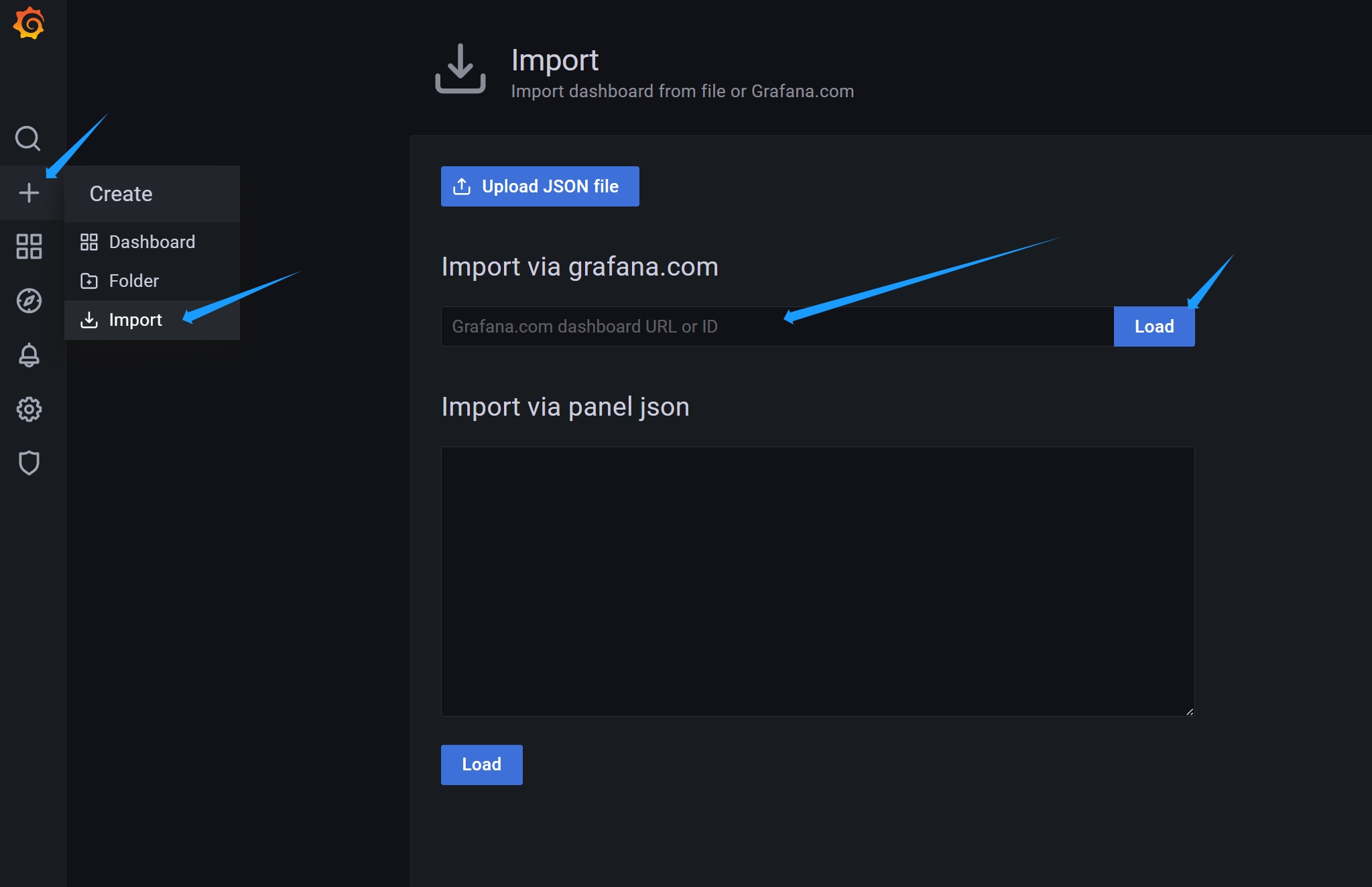
最佳实践Grafana应用市场-高效导入仪表盘
-
需求
- Grafana支持很多数据源,但是不同中间件太多,每个panel又很多选项
- 一个个配置对于开发新手和老手都是比较麻烦的,能不能达到复用呢?
-
Grafana应用市场
- 地址:https://grafana.com/grafana/dashboards/
- 是Grafana社区和其他用户分享的可装载的仪表板和面板集合
- 当安装应用程序市场模板时,Grafana会自动安装和配置自定义仪表板面板,并可以自动设置相关数据源
- 应用市场模板可以是来自Grafana仓库、别人的GitHub仓库、开源项目或个人创建的
- Grafana模板使得共享可装载的仪表板变得容易,从而帮助用户减少了工作量,并促进了最佳设置和最佳配置的使用


Grafana的Alert监控告警
-
需求
- Alertmanager是Prometheus的一个组件,用于定义和发送告警通知,Grafana也有告警功能,两个组件各有优缺点
- Grafana更适合于互联网领域的常规监控系统,而Alertmanager更适合于大规模或更复杂的告警处理场景
- 如果需要告警功能并且已经使用Grafana进行数据可视化,则可以使用Grafana作为告警处理工具
-
两者对比
- Grafana
- 优点
- 简单易用,Grafana的告警规则配置界面直观易懂,可以方便地设置告警的触发条件、持续时间和通知方式等。
- 定制性强,Grafana的告警规则支持自定义查询和指标,使得监控系统的告警范围更加广泛。
- 能够对告警事件进行统计和可视化处理,在Grafana中可以方便地对告警事件进行统计,同时还可以进行实况监控和定期报告等操作。
- 缺点
- 不支持高级告警逻辑。Grafana只能识别基于简单算术或表达式的逻辑,无法支持更复杂的逻辑。
- 设计初衷不是作为告警处理工具,Grafana更多地是作为数据可视化工具
- 核心功能是数据分析和展示,并不是专门的告警处理工具,因此不太适合大规模或复杂的告警处理场景
- 可扩展性不够,无法满足比较复杂、高级的告警规则设计
- 优点
- Alertmanager
- 优点
- 提供高级告警逻辑功能,支持许多常用的高级告警逻辑,如静默、抑制和聚合等。
- 支持多通道分发告警,支持将告警通知分发到多个通道,如电子邮件,短信等,能够满足不同场景下的需求。
- 可靠性高,提供多种保护机制,如去重、失败重试和自动恢复,确保告警能够可靠地传送给相应的接收方。
- 支持高度可扩展性,可以与各种 monitoring system 集成使告警触发进一步个性化
- 缺点
- 复杂和难以部署,Alertmanager的配置比Grafana更复杂,需要深入了解监控系统和告警系统。
- 学习成本高,Alertmanager需要学习更多的知识和技能才能掌握
- 不善于定义静态监控告警,对于 Dashboard 监控告警,它可能不太适合。
- 优点
- Grafana
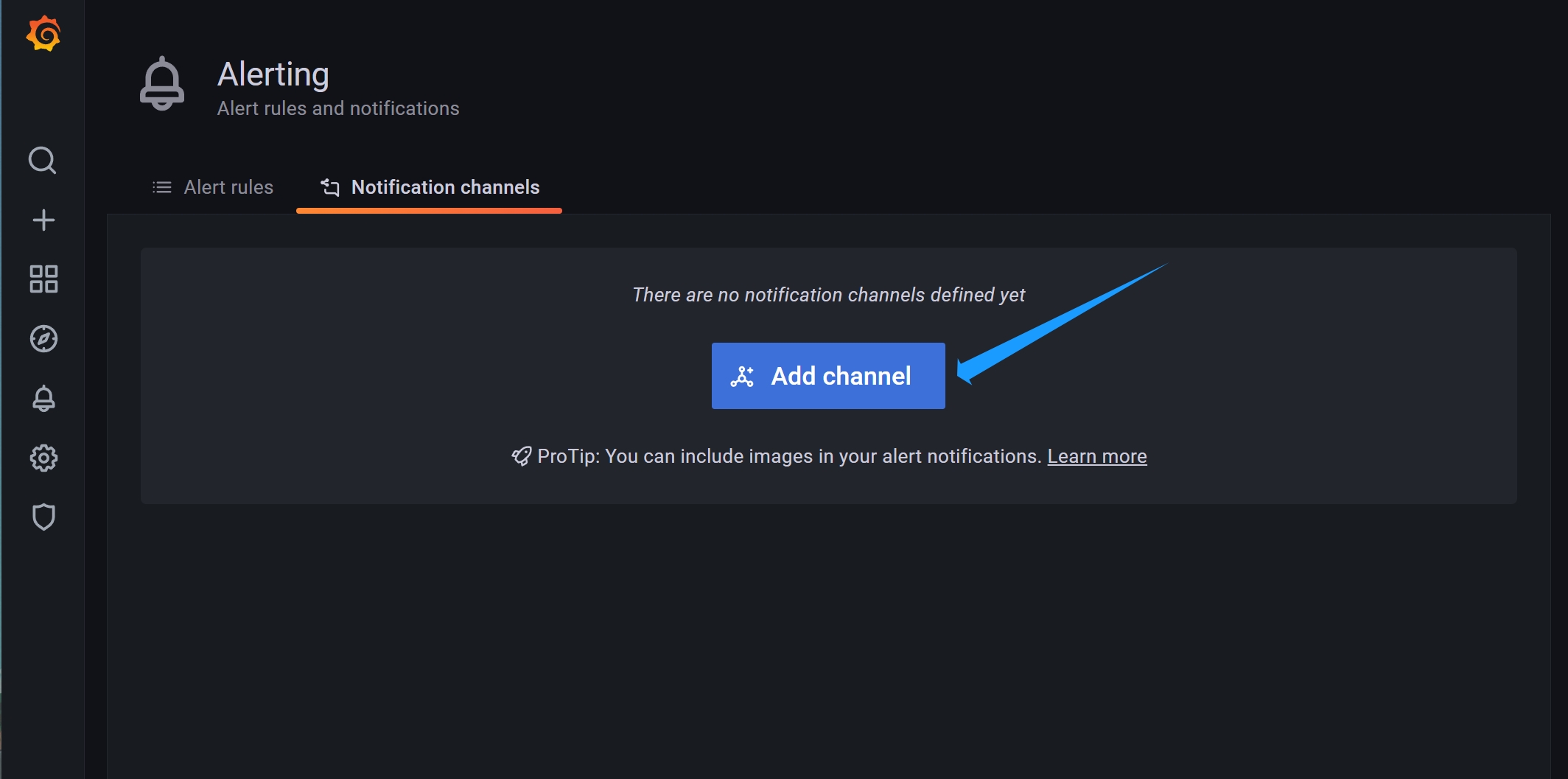
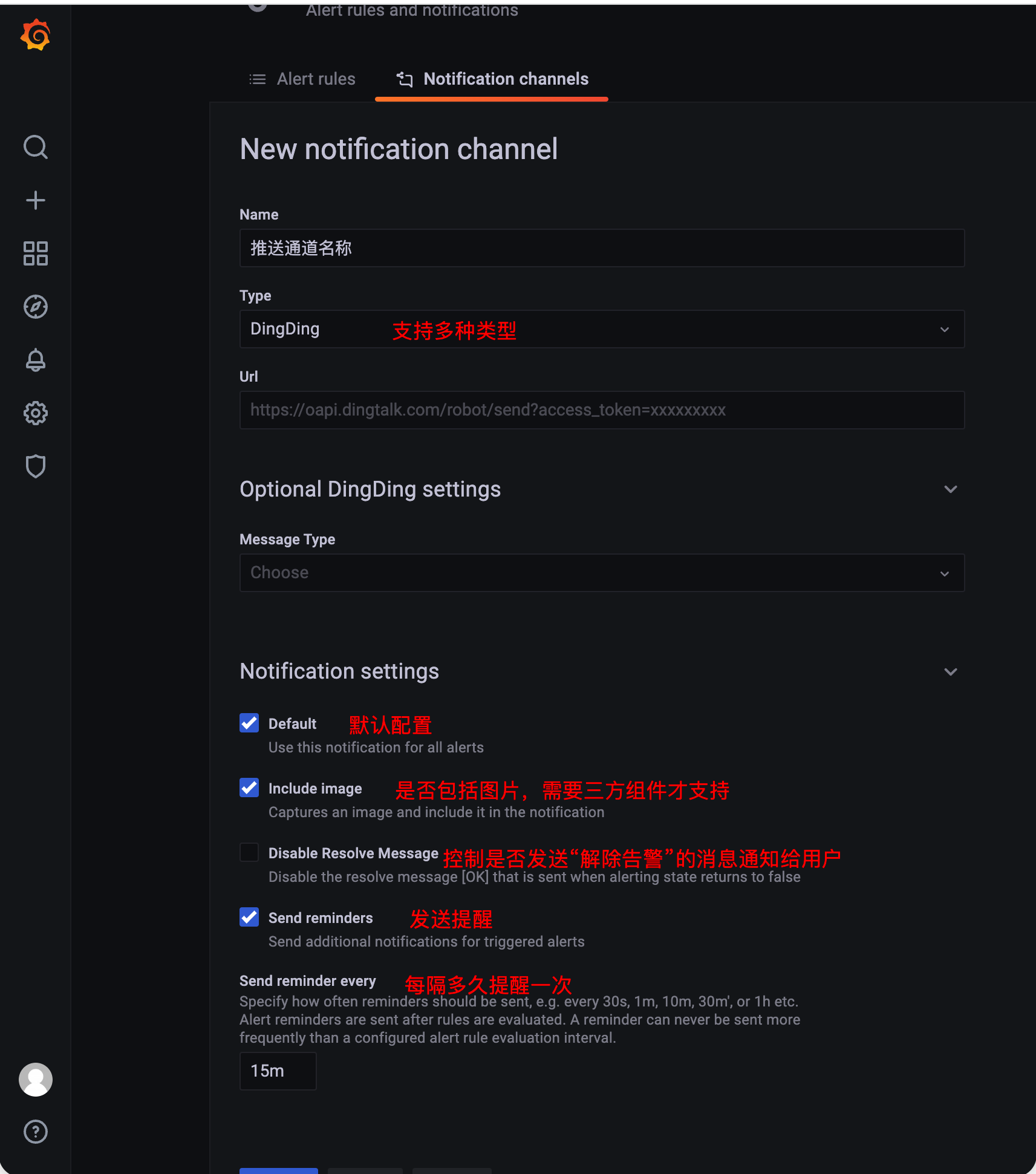
Grafana的告警界面介绍:由 告警规则+推送通道 组成
-
Alert Rules 告警规则
- 根据panel面板进行配置告警规则,满足相关条件则会触发告警,并通过推送通道推送给对应的接受者
- 注意:查询条件使用模版变量,会识别不了,导致告警创建失败,可以进行硬编码替换模版变量

Notifications Channel 推送通道
- 支持多个通知方式,用于向用户推送告警信息,可以根据不同的应用场景选择适合的通知渠道
- 比如:Email、Slack、钉钉、Webhook等
Grafana之钉钉群告警机器人
- 使用Grafana的alert告警模块,检测应用是否存活
- 配置自动告警机器人,如果应用宕机超过1分钟,推送到钉钉群
- 注意:一般只有graph panel 也就是图表面板(一般都是折线图和柱状图或者点状图)可以添加Alert ,其他面板不支持。
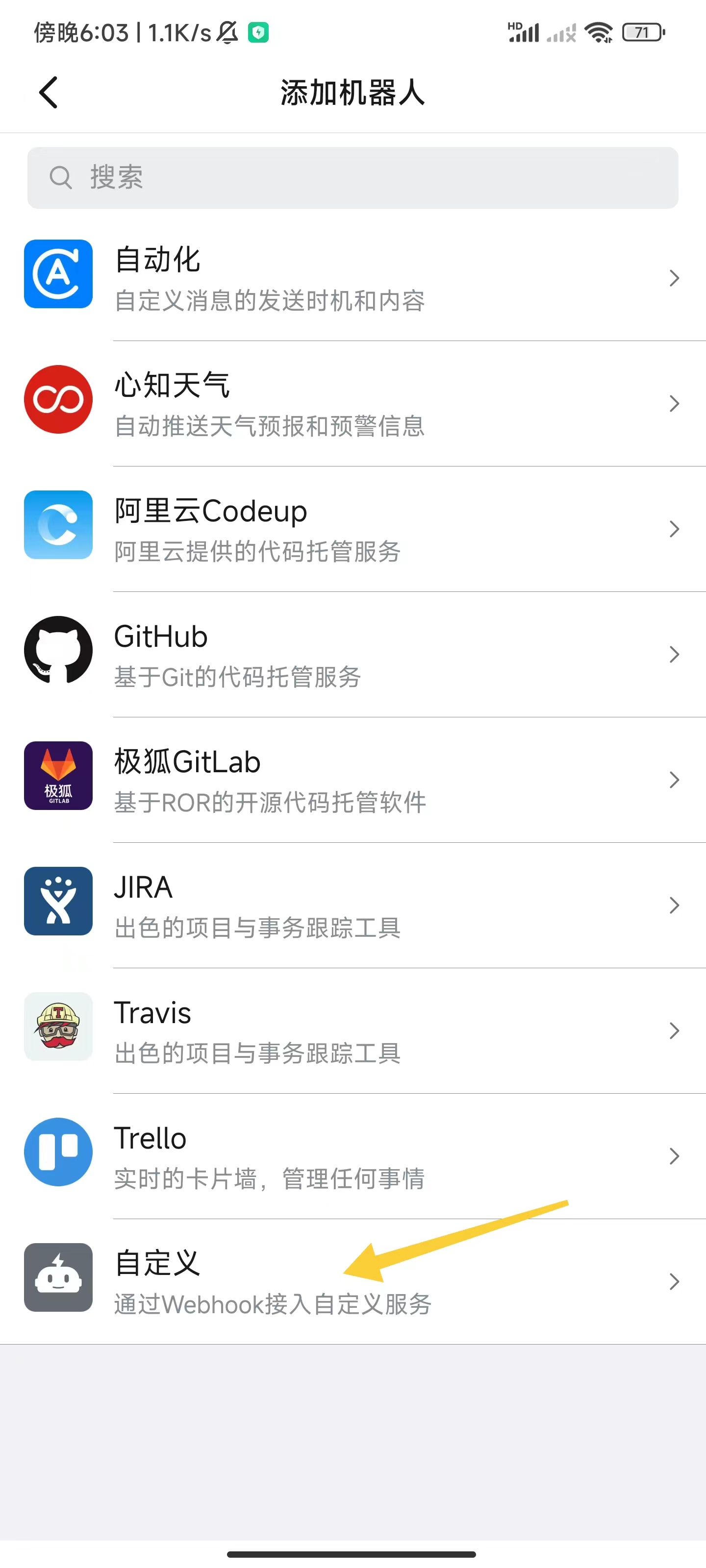
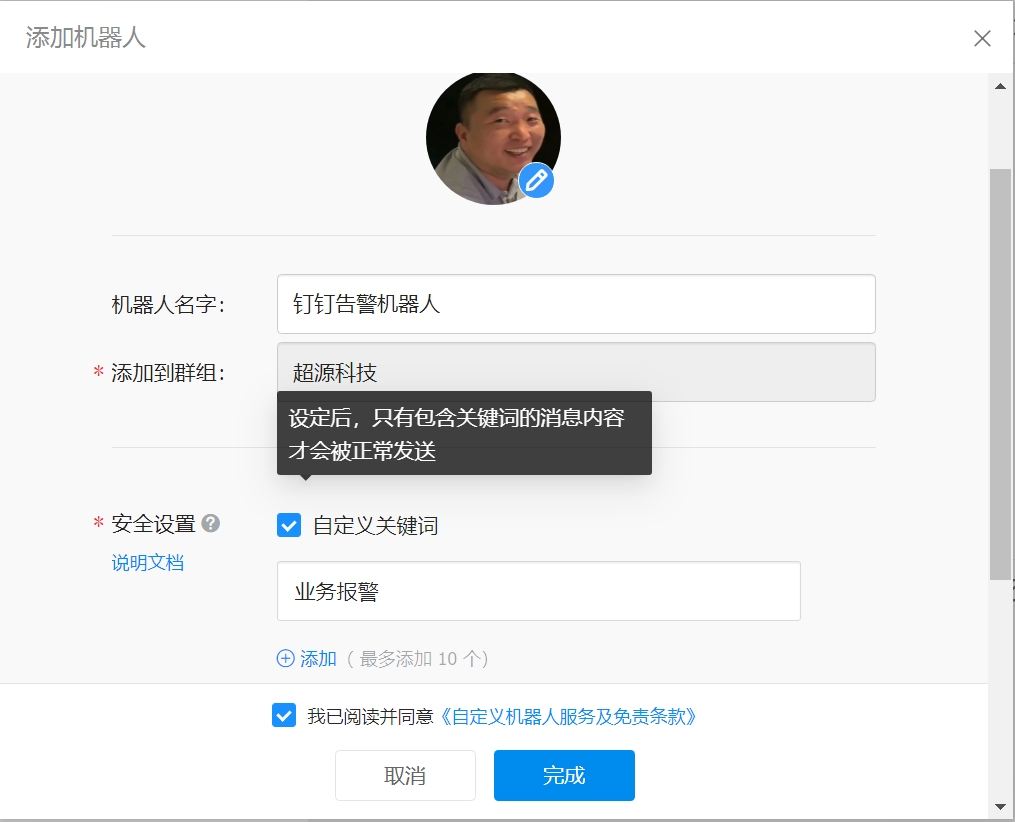
实战步骤
-
创建钉钉告警机器人,获取webhook地址

问题修复
- 点击群告警信息没法直接进到告警页面
- 解决方案:配置默认跳转路径,使用root用户进入容器修改配置文件
# 进入容器
docker exec -u 0 -it soulboy-grafana /bin/bash
#通过容器id进入
docker exec -u 0 -it 940d7837c3aa /bin/bash
# 默认是localhost
bash-5.1# vi /usr/share/grafana/conf/defaults.ini
domain = 192.168.10.20
#通过容器id重启
exit
docker restart 940d7837c3aa