Sleuth
全链路监控
微服务架构下,服务按照不同的维度进行拆分,一次请求可能会涉及多个服务,并且可能由不同的团队开发,使用不同的编程语言,可能部署在几千个节点上,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。
APM(Application Performance Management),其中最出名的是谷歌公开的论文提到的 Dapper。Dapper 论文中对实现一个分布式跟踪系统提出了如下需求:
- 性能低损耗:分布式跟踪系统对服务的性能损耗应该尽可能做到可以忽略不计,尤其是对性能敏感的应用不能产生损耗。
- 对应用透明:即要求尽可能用非侵入的方式来实现跟踪,尽可能做到业务代码的低侵入,对业务开发人员应该做到透明化。
- 可伸缩性:是指不能随着微服务和集群规模的扩大而使分布式跟踪系统瘫痪。
- 跟踪数据可视化和迅速反馈:即要有可视化的监控界面,从跟踪数据收集、处理到结果的展现尽量做到快速,这样就可以对系统的异常状况作出快速反应。
- 持续监控:即要求分布式跟踪系统必须是 7 *24 小时工作的,佛足额将难以定位到系统偶尔抖动的行为。
Spring Cloud Sleuth
是 Spring Cloud 的分布式调用链路解决方案,它从 Dapper、Zipkin、HTrace 中借鉴了很多思路。Sleuth 对于大部分用户来说都是透明的,系统间交互信息都能被系统采集。用户可以通过日志文件获取链路数据,也可以将数据发给远程服务进行统一收集展示。
术语
- Span:基本工作单位。 比如:发送一次 RPC 请求就是一个新的 Span。 Span 通过一个 64 位的 ID 标识,还包含有描述、事件时间戳、标签、调用它的 Span 的 ID,处理器 ID(一般指 IP 地址)。注意:第一个 Span 是 root span,他的 ID 值和 trace 的 ID 值一样。
- Trace:一系列 Span 组成的树状结构。简而言之,就是第一次请求全链路。
- Annotation:标注,用来描述事件的实时状态。
Sleuth 原理
Sleuth 通过 Trace 定义一次调用链路,根据它的信息,可以得知有多少个系统参与了该业务处理。而系统间的调用顺序和时间戳信息,则是通过 Span 来记录的,Trace 和 Span 的信息经过整合,就能知道该业务的完整调用链。
Brave 和 Zipkin
Brave 是一个用于捕捉分布式系统之间调用信息的工具库,然后将这些信息以 Span 的形式发给 Zipkin。
Zipkin 是一个基于 Google Dapper 论文设计的分布式跟踪系统,他首节系统的延迟数据并提展示界面,一边用户排查问题。
入门案例
添加 Maven 依赖 order_service、product_service 中项目添加依赖 重启 Eureka
<!--sleuth依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
解决日志不打印问题
private final Logger logger = LoggerFactory.getLogger(getClass()); //使用org.slf4j.Logger;
logger.info("order save "); //在调用方法开始前添加
访问
http://192.168.31.230:9000/apigateway/order/api/v1/order/save?user_id=2&product_id=2&token=asdasd
order_service 信息显示
2019-07-03 15:15:03.452 INFO [order-service,9214c02f2b9bb9bd,00de6bce5012f338,false] 16692 --- [derController-2] n.x.o.s.impl.ProductOrderServiceImpl : order save
product_service 信息显示
2019-07-03 15:15:03.446 INFO [product-service,9214c02f2b9bb9bd,b2b39f84c74c3ed7,false] 4216 --- [nio-8771-exec-3] n.x.p.service.impl.ProductServiceImpl : product findById
信息结构分析
[order-service,9214c02f2b9bb9bd,00de6bce5012f338,false]
- 第一个值,spring.application.name 的值
- 第二个值,96f95a0dd81fe3ab ,sleuth 生成的一个 ID,叫 Trace ID,用来标识一条请求链路,一条请求链路中包含一个 Trace ID,多个 Span ID
- 第三个值,852ef4cfcdecabf3、spanid 基本的工作单元,获取元数据,如发送一个 http
- 第四个值:false,是否要将该信息输出到 zipkin 服务中来收集和展示。
Zipkin 的部署
基于 docker 部署
http://192.168.31.210:9411/zipkin/
docker run -d -p 9411:9411 openzipkin/zipkin
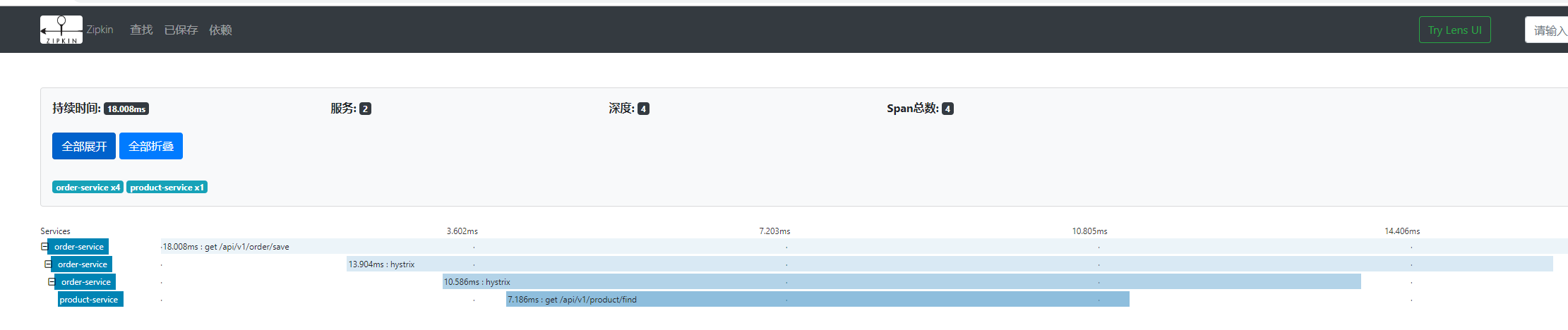
链路追踪 Sleuth+Zipkin
sleuth 收集跟踪信息通过 http 请求发送给 zipkin server,zipkinserver 进行跟踪信息的存储以及提供 Rest API 即可,Zipkin UI 调用其 API 接口进行数据展示,zipkinserver 默认采用存储是内存,可也用 MySQL、或者 Elasticsearch 等存储。
添加依赖
<!--sleuth依赖包含sleuth,因此可以把sleuth删除-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置 zipkin.base-url(sleuth 收集跟踪信息通过 http 请求发送给 zipkin)