
XXL-Job
定时任务
通过时间表达式这一方式来进行任务调度的被称为定时任务。
在平常的业务场景当中,经常有一些场景需要使用到定时任务,比如:在某个时间点会发送优惠券、发送短信等等的一些业务操作。又比如:比如一些支付系统,需要在每天的凌晨1点来进行对前一天的清算。
分类
- 单机定时任务
- 单机的容易实现,但应用于集群环境做分布式部署,就会带来重复执行
- 解决重复执行的方案有很多,比如加锁、数据库等,但是增加了很多非业务逻辑
- 分布式调度(分布式定时任务)
- 把需要处理的计划任务放入到统一的平台,实现集群管理调度与分布式部署的定时任务 叫做分布式定时任务
- 支持集群部署、高可用、并行调度、分片处理等
常见定时任务
- 单机:Java自带的java.util.Timer类配置比较麻烦,时间延后问题
- 单机:ScheduledExecutorService
- 是基于线程池来进行设计的定时任务类,在这里每个调度的任务都会分配到线程池里的一个线程去执行该任务,并发执行,互不影响
- 单机:SpringBoot框架自带
- SpringBoot使用注解方式开启定时任务
- 启动类里面 @EnableScheduling开启定时任务,自动扫描
- 定时任务业务类 加注解 @Component被容器扫描
- 定时执行的方法加上注解 @Scheduled(fixedRate=2000) 定期执行一次
为什么需要任务调度平台
因为在传统的Java当中,传统的定时任务实现方案,像上述的Timer、Quartz等,它们都有不少缺点。
- 不支持集群、不支持统计、没有管理的平台、也没有报警、监控等等
- 在分布式架构当中,有一些场景是需要用到分布式的任务调度的,在同一个服务器中的多个实例任务之间存在着互斥,需要进行统一的调度,所以任务调度需要支持高可用、监控、故障告警等一系列措施。
- 需要统一管理和追踪各个的服务节点之间任务调度的结果,并保存记录任务信息等等
常见分布式调度平台
Quartz
- Quartz关注点在于定时任务而并非是数据,并没有一套根据数据化处理而定的流程
- 虽然可以实现数据库作业的高可用,但是缺少了分布式的并行调度功能,相对弱点
- 不支持任务分片、没UI界面管理,并行调度、失败策略等也缺少
TBSchedule
- 这个是阿里早期开源的分布式任务调度系统,使用的是timer而不是线程池执行任务调度,使用timer在处理异常的时候是有缺陷的,但TBSchedule的作业类型比较单一,文档也缺失得比较严重
ScheduleX(目前阿里内部使用,阿里云商业化产品)
- 阿里云也有商业化版本: https://help.aliyun.com/product/147760.html
Elastic-job
当开发的分布式任务调度系统,功能强大,采用的是zookeeper实现分布式协调,具有高可用与分片。2020年6月,ElasticJob的四个子项目已经正式迁入Apache仓库。由 2 个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成:
- ElasticJob-Lite 定位为轻量级无中心化解决方案,使用jar的形式提供分布式任务的协调服务;
- ElasticJob-Cloud 使用 Mesos 的解决方案,额外提供资源治理、应用分发以及进程隔离等服务
XXL-JOB
大众点评的员工徐雪里在15年发布的分布式任务调度平台,是轻量级的分布式任务调度框架,目标是开发迅速、简单、清理、易扩展; 老版本是依赖quartz的定时任务触发,在v2.1.0版本开始 移除quartz依赖
| 对比项 | XXL-JOB | elastic-job |
|---|---|---|
| 并行调度 | 调度系统多线程并行 | 任务分片的方式并行 |
| 弹性扩容 | 使用Quartz基于数据库分布式功能 | 通过zookeeper保证 |
| 高可用 | 通过DB锁保证 | 通过zookeeper保证 |
| 阻塞策略 | 单机串行/丢弃后续的调度/覆盖之前的调度 | 执行超过zookeeper的session timeout时间的话,会被清除,重新进行分片 |
| 动态分片策略 | 以执行器为维度进行分片、支持动态的扩容 | 平均分配/作业名hash分配/自定义策略 |
| 失败处理策略 | 失败告警/失败重试 | 执行完毕后主动获取未分配分片任务 服务器下线后主动寻找可以用的服务器执行任务 |
| 监控 | 支持 | 支持 |
| 日志 | 支持 | 支持 |
技术选型
- XXL-Job和Elastic-Job都具有广泛的用户基础和完善的技术文档,都可以满足定时任务的基本功能需求
- xxl-job侧重在业务实现简单和管理方便,容易学习,失败与路由策略丰富, 推荐使用在用户基数相对较少,服务器的数量在一定的范围内的场景下使用
- elastic-job关注的点在数据,添加了弹性扩容和数据分片的思路,更方便利用分布式服务器的资源, 但是学习难度较大,推荐在数据量庞大,服务器数量多的时候使用
核心设计思想
xxl-job的设计思想
“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性。
- 将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
- 将任务抽象成分散的JobHandler,交由“执行器”统一管理。“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
架构图
- 调度中心
- 负责管理调度的信息,按照调度的配置来发出调度请求
- 支持可视化、简单的动态管理调度信息,包括新建、删除、更新等,这些操作都会实时生效,同时也支持监控调度结果以及执行日志。
- 执行器
- 负责接收请求并且执行任务的逻辑。任务模块专注于任务的执行操作等等,使得开发和维护更加的简单与高效
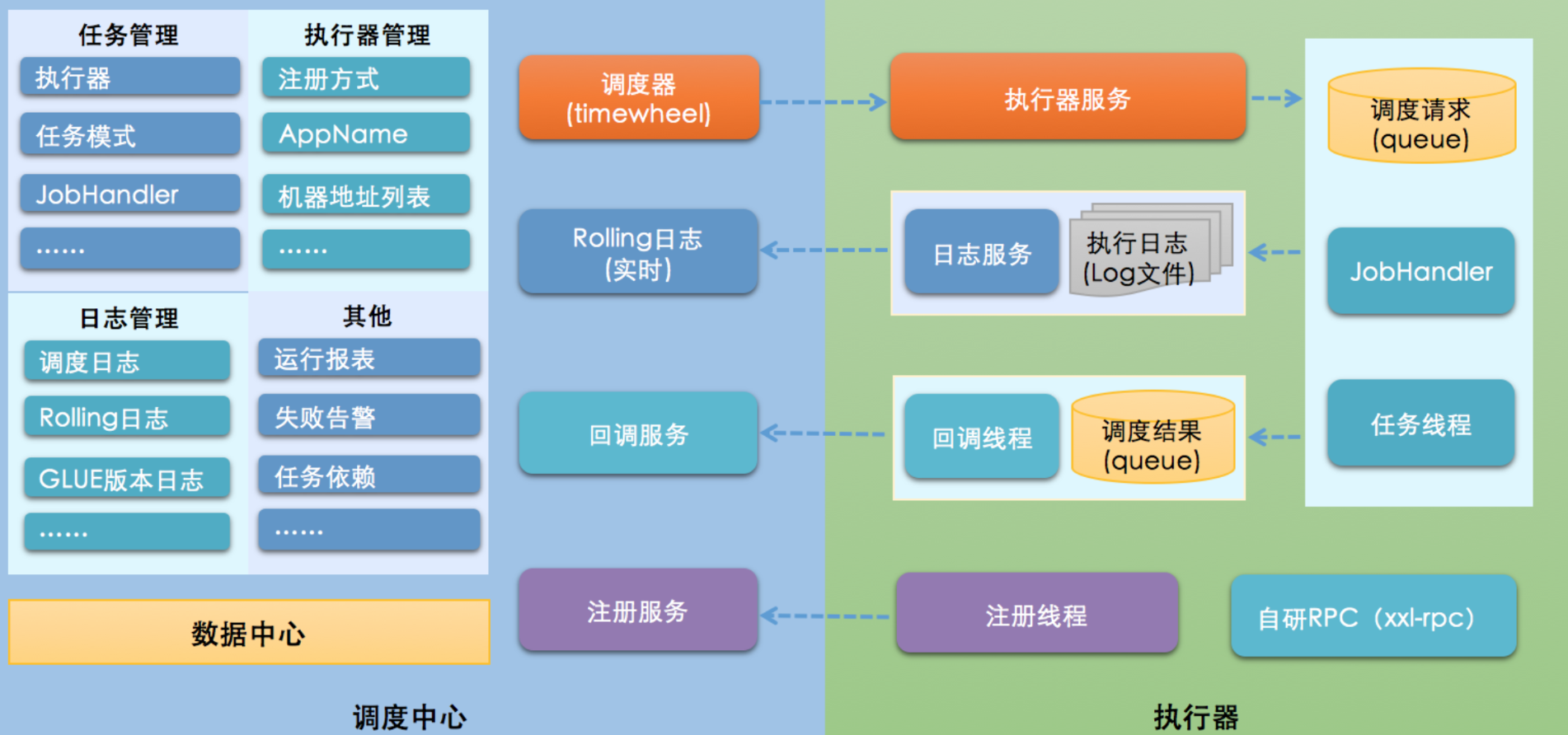
- 调度中心HA(中心式):调度采用了中心式进行设计,“调度中心”支持集群部署,可保证调度中心HA
- 执行器HA(分布式):任务分布式的执行,任务执行器支持集群部署,可保证任务执行HA
- 触发策略:有Cron触发、固定间隔触发、固定延时触发、API事件触发、人工触发、父子任务触发
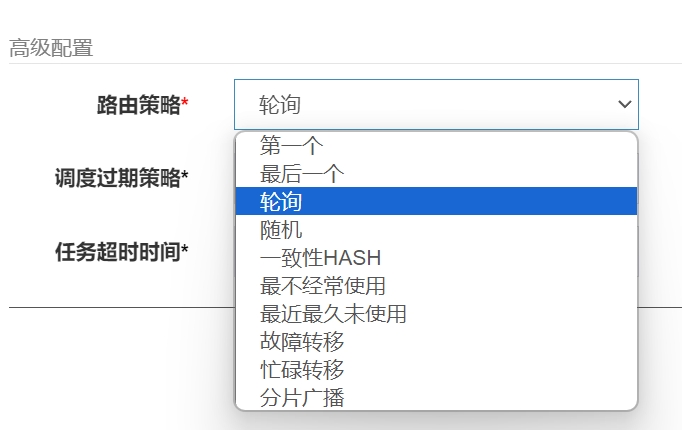
- 路由策略:执行器在集群部署的时候提供了丰富的路由策略,如:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用LFU、最久未使用LRU、故障转移等等
- 故障转移:如果执行器集群的一台机器发生故障,会自动切换到一台正常的执行器发送任务调度
- Rolling实时日志的监控:支持rolling方式查看输入的完整执行日志
- 脚本任务:支持GLUE模式开发和运行脚本任务,包括Shell、python、node.js、php等等类型脚本
部署
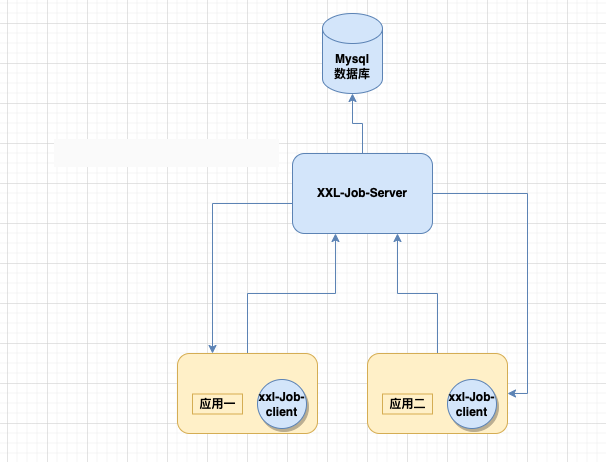
目录概览
| 目录名 | 功能 |
|---|---|
| doc | xxl-job的文档资料,包括了数据库的脚本 |
| xxl-job-core | 公共jar包依赖 |
| xxl-job-admin | 调度中心,项目源码,是Springboot项目,可以直接启动 |
| xxl-job-executor-samples | 执行器,是Sample实例项目,里面的Springboot工程可以直接启动,也可以在该项目的基础上进行开发,也可以将现有的项目改造成为执行器项目 |
数据库概览
| 库名 | 功能 |
|---|---|
| xxl_job_group | 执行器信息表,用于维护任务执行器的信息 |
| xxl_job_info | 调度扩展信息表,主要是用于保存xxl-job的调度任务的扩展信息,比如说像任务分组、任务名、机器的地址等等 |
| xxl_job_lock | 任务调度锁表 |
| xxl_job_log | 日志表,主要是用在保存xxl-job任务调度历史信息,像调度结果、执行结果、调度入参等等 |
| xxl_job_log_report | 日志报表,会存储xxl-job任务调度的日志报表,会在调度中心里的报表功能里使用到 |
| xxl_job_logglue | 任务的GLUE日志,用于保存GLUE日志的更新历史变化,支持GLUE版本的回溯功能 |
| xxl_job_registry | 执行器的注册表,用在维护在线的执行器与调度中心的地址信息 |
| xxl_job_user | 系统的用户表 |
初始化数据
### 运行Mysql
docker run \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql \
--restart=always \
-d mysql:5.7
### 运行SQL
#
# XXL-JOB v2.3.0
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
xxl-job-admin/src/main/resources/application.properties
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://192.168.10.57:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### xxl-job, access token
xxl.job.accessToken=abc1024.pub
com.xxl.job.admin.XxlJobAdminApplication
15:24:23.703 logback [main] INFO o.s.b.w.e.tomcat.TomcatWebServer - Tomcat started on port(s): 8080 (http) with context path '/xxl-job-admin'
15:24:23.714 logback [main] INFO c.x.job.admin.XxlJobAdminApplication - Started XxlJobAdminApplication in 1.29 seconds (JVM running for 1.73)
15:24:28.001 logback [xxl-job, admin JobScheduleHelper#scheduleThread] INFO c.x.j.a.c.thread.JobScheduleHelper - >>>>>>>>> init xxl-job admin scheduler success.
src/main/resources/logback.xml (路径加一个.)
<property name="log.path" value="./data/applogs/xxl-job/xxl-job-admin.log"/>
访问地址
http://192.168.10.88:8080/xxl-job-admin
账户: admin
密码: 123456
SpringBoot整合XXL-Job
Maven整合配置
依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
src/main/resources/logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="false" scan="true" scanPeriod="1 seconds">
<contextName>logback</contextName>
<property name="log.path" value="./data/logs/xxl-job/app.log"/>
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zip</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n
</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="console"/>
<appender-ref ref="file"/>
</root>
</configuration>
application.properties
server.port=8081
#----------xxl-job配置--------------
logging.config=classpath:logback.xml
# 调度中心部署地址,多个配置逗号分隔 "http://address01,http://address02"
xxl.job.admin.addresses=http://192.168.10.88:8080/xxl-job-admin
# 执行器token,非空时启用 xxl-job, access token
xxl.job.accessToken=abc1024.pub
# 执行器app名称,和控制台那边配置一样的名称,不然注册不上去
xxl.job.executor.appname=abc1024-shop
# [选填]执行器注册:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。
# 从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
# [选填]执行器IP :默认为空表示自动获取IP(即springboot容器的ip和端口,可以自动获取,也可以指定),多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务",
xxl.job.executor.ip=192.168.10.88
# [选填]执行器端口号:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
# 执行器日志文件存储路径,需要对该路径拥有读写权限;为空则使用默认路径
xxl.job.executor.logpath=./data/logs/xxl-job/executor
# 执行器日志保存天数
xxl.job.executor.logretentiondays=30
配置类 net/xdclass/xdclassjob/config/XxlJobConfig.java
package net.xdclass.xdclassjob.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 小滴课堂,愿景:让技术不再难学
*
* @Description
* @Author 二当家小D,微信:xdclass6
* @Remark 有问题直接联系我,源码-笔记-技术交流群
* @Version 1.0
**/
@Configuration
public class XxlJobConfig {
private Logger log = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
//旧版的有bug
//@Bean(initMethod = "start", destroyMethod = "destroy")
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
上手XXL-Job分布式调度任务
注解介绍
在 Spring Bean 实例中,开发 Job 方法方式格式要求为:
public ReturnT<String> execute(String param)
为 Job 方法添加注解 (注解value值是调度中心新建任务的 JobHandler 属性的值)
@XxlJob(value="自定义jobHandler名称", init = "handler初始化方法", destroy = "handler 销毁方法")
net/xdclass/xdclassjob/job/MyJobHandler.java
package net.xdclass.xdclassjob.job;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
public class MyJobHandler {
private Logger log = LoggerFactory.getLogger(MyJobHandler.class);
/**
* XXJ-Job核心方法
* @param param
* @return
*/
@XxlJob(value = "demoJobHandler", init = "init", destroy = "destroy")
public ReturnT<String> execute(String param) {
log.info("abc1024-shop execute 任务方法触发成功" + LocalDateTime.now());
return ReturnT.SUCCESS;
}
/**
* 初始化方法
*/
private void init() {
log.info("init 方法调用成功 >>>>>>");
}
/**
* 销毁方法
*/
private void destroy() {
log.info("destroy 方法调用成功 >>>>>>");
}
}
任务管理器新增
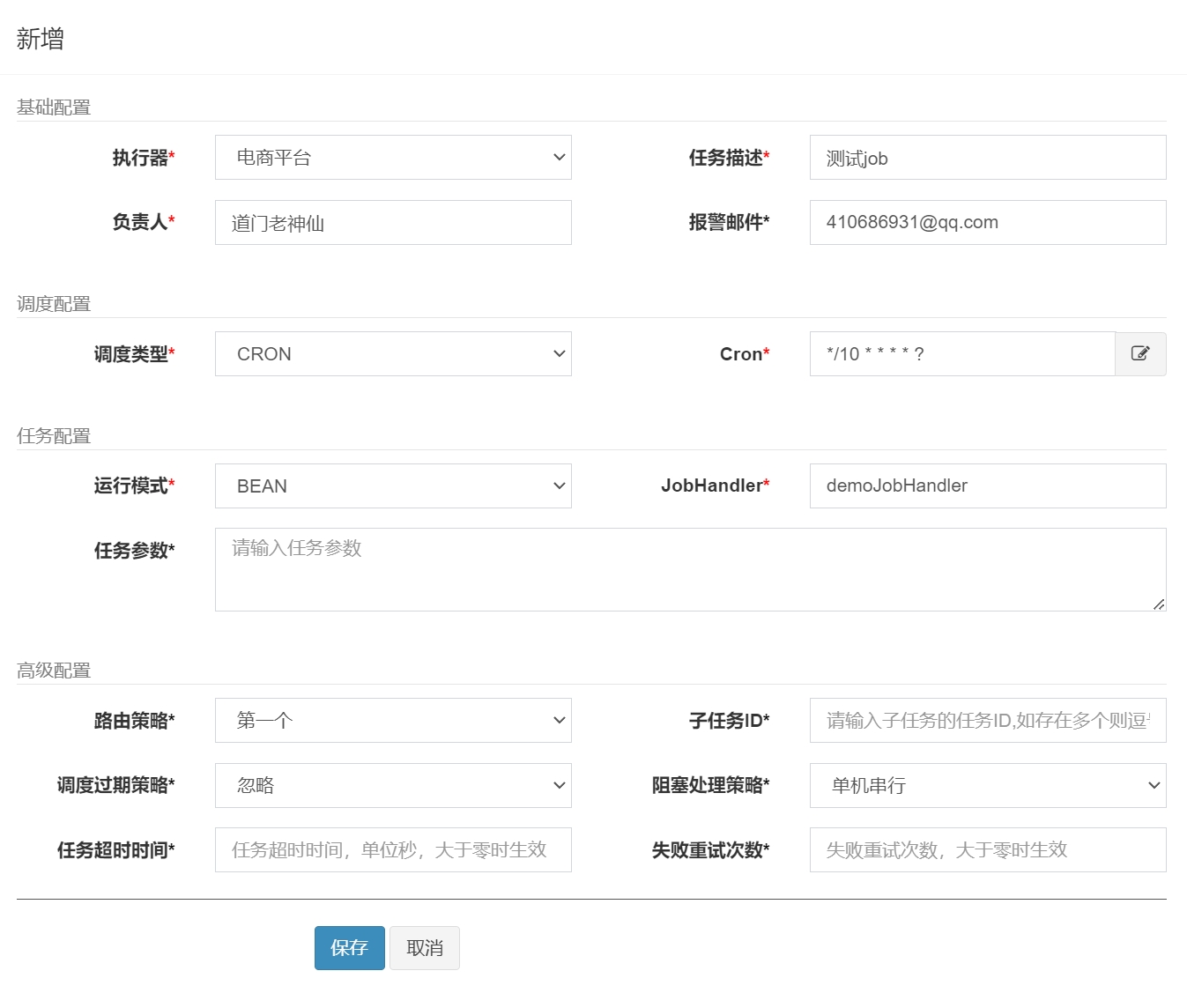
控制台输出
12:40:16.534 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - init 方法调用成功 >>>>>>
12:40:16.537 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - abc1024-shop execute 任务方法触发成功2024-01-02T12:40:16.537122900
12:45:58.008 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - destroy 方法调用成功 >>>>>>
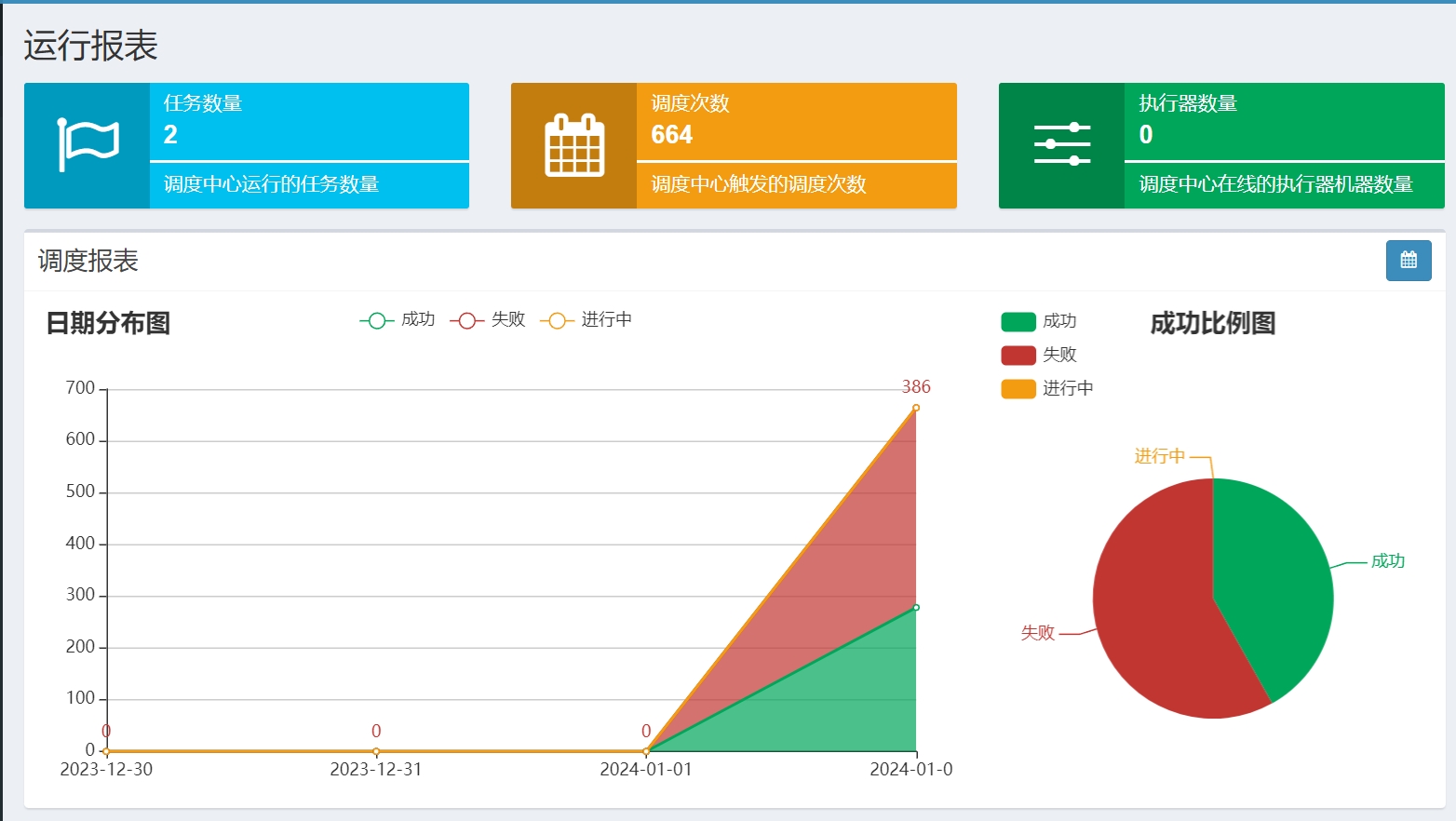
调度报表
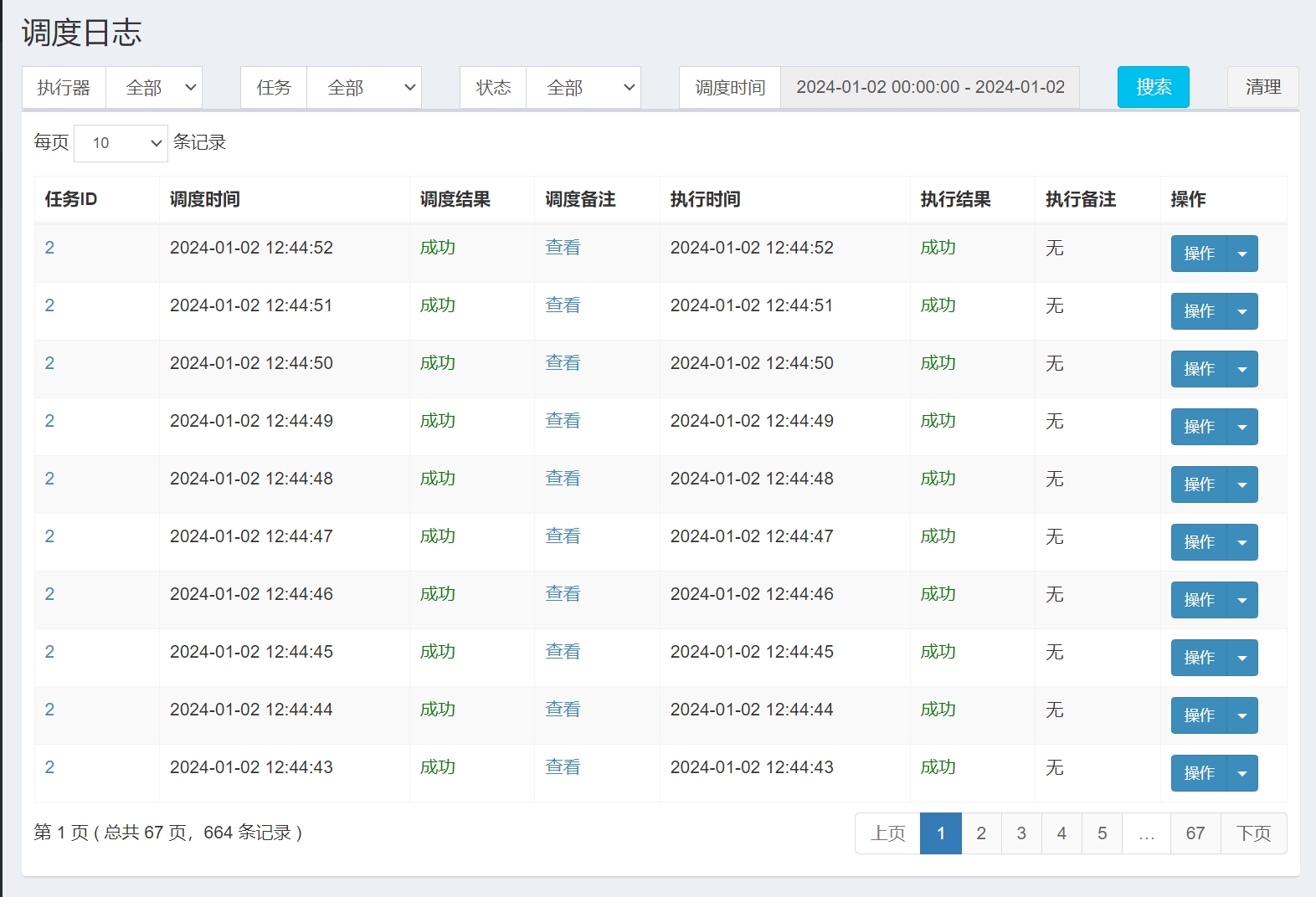
调度日志
多执行器

多种路由策略
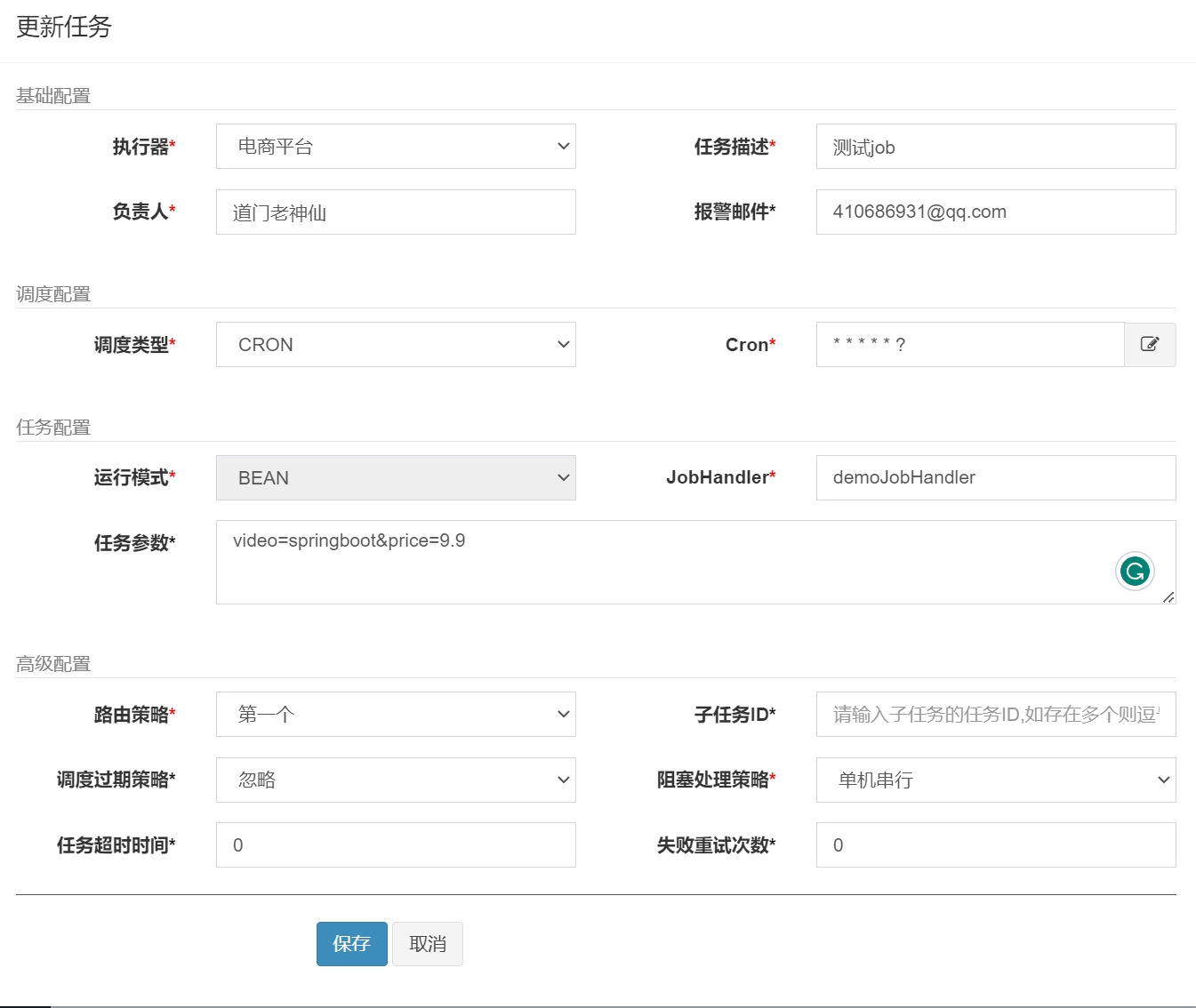
参数传递
调度中心配置
执行器代码
package net.xdclass.xdclassjob.job;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
public class MyJobHandler {
private Logger log = LoggerFactory.getLogger(MyJobHandler.class);
/**
* XXJ-Job核心方法
* @return
*/
@XxlJob(value = "demoJobHandler", init = "init", destroy = "destroy")
public ReturnT<String> execute() {
//获取执行参数
String param = XxlJobHelper.getJobParam();
System.out.println("param=" + param);
log.info("abc1024-shop execute 任务方法触发成功" + LocalDateTime.now());
return ReturnT.SUCCESS;
}
/**
* 初始化方法
*/
private void init() {
log.info("init 方法调用成功 >>>>>>");
}
/**
* 销毁方法
*/
private void destroy() {
log.info("destroy 方法调用成功 >>>>>>");
}
}
控制台输出
13:32:40.157 logback [xxl-rpc, EmbedServer bizThreadPool-1452437736] INFO c.x.job.core.executor.XxlJobExecutor - >>>>>>>>>>> xxl-job regist JobThread success, jobId:2, handler:com.xxl.job.core.handler.impl.MethodJobHandler@6b649efa[class net.xdclass.xdclassjob.job.MyJobHandler#execute]
13:32:40.157 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - init 方法调用成功 >>>>>>
param=video=springboot&price=9.9
13:32:40.161 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - abc1024-shop execute 任务方法触发成功2024-01-02T13:32:40.161531600
调度日志配置
执行器代码中可以使用打印日志追加到调度中心的调度日志中
/**
* XXJ-Job核心方法
* @return
*/
@XxlJob(value = "demoJobHandler", init = "init", destroy = "destroy")
public ReturnT<String> execute() {
//获取执行参数
String param = XxlJobHelper.getJobParam();
System.out.println("param=" + param);
log.info("abc1024-shop execute 任务方法触发成功" + LocalDateTime.now());
//打印日志!!!
XxlJobHelper.log("打印执行日志:param=" + param);
return ReturnT.SUCCESS;
}


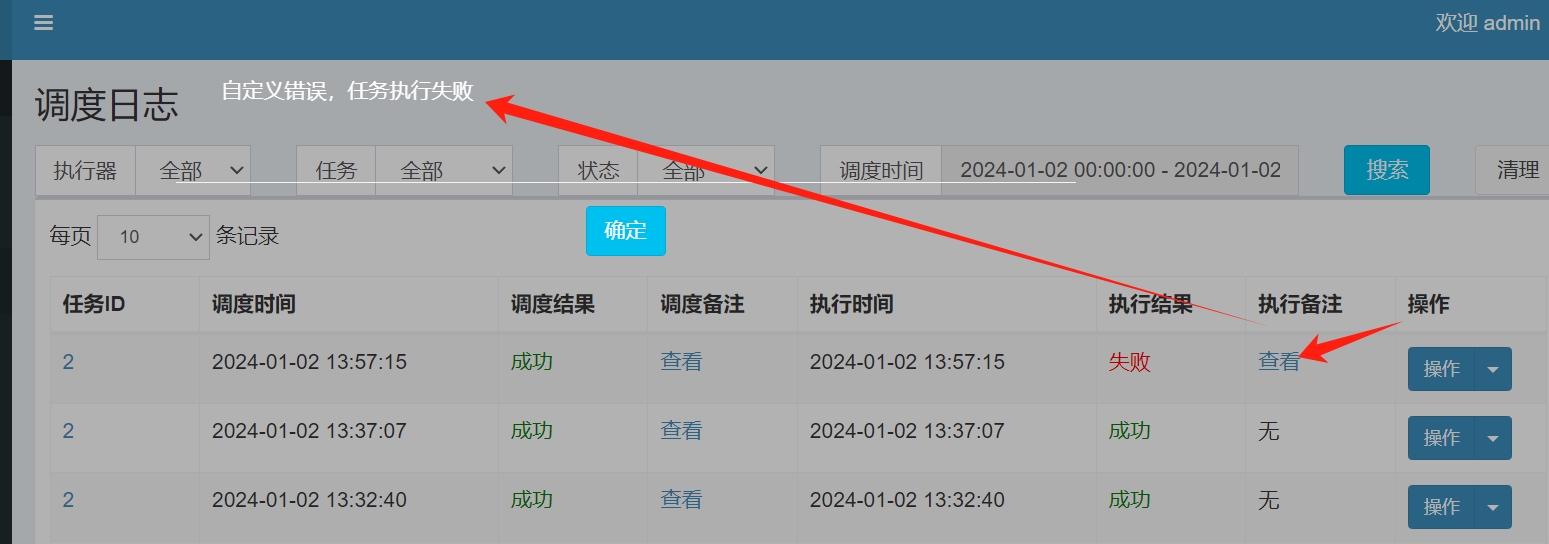
调度结果、执行结果
默认任务结果为 "成功" 状态,不需要主动设置
- 如想设置任务结果为失败,可以通过 "XxlJobHelper.handleFail
- 如想设置任务结果为成功,handleSuccess"

执行器代码:自定义执行错误
/**
* XXJ-Job核心方法
* @return
*/
@XxlJob(value = "demoJobHandler", init = "init", destroy = "destroy")
public void execute() {
//获取执行参数
String param = XxlJobHelper.getJobParam();
System.out.println("param=" + param);
log.info("abc1024-shop execute 任务方法触发成功" + LocalDateTime.now());
//打印日志!!!
XxlJobHelper.log("打印执行日志:param=" + param);
//自定义执行错误
XxlJobHelper.handleFail("自定义错误,任务执行失败");
//自定义执行成功
//XxlJobHelper.handleSuccess("任务执行成功");
//return ReturnT.SUCCESS;
}
集群HA
为了避免单点故障,任务调度系统通常需要通过集群实现系统高可用,由于任务调度系统的特殊性,“调度”和“任务”两个模块需要均支持集群部署,由于职责不同,因此各自集群侧重点也有有所不同。
- 调度中心集群:目标为避免调度模块单点故障,集群节点需要通过锁或命名服务保证单个任务的单次触发,只在其中一个节点上生效,以防止任务的重复触发。
- 执行器集群:目标为避免任务模块单点故障,进一步可以通过自定义路由策略实现Failover等高级功能,从而在执行器某台机器节点故障时自动转移不会影响到任务的正常触发执行
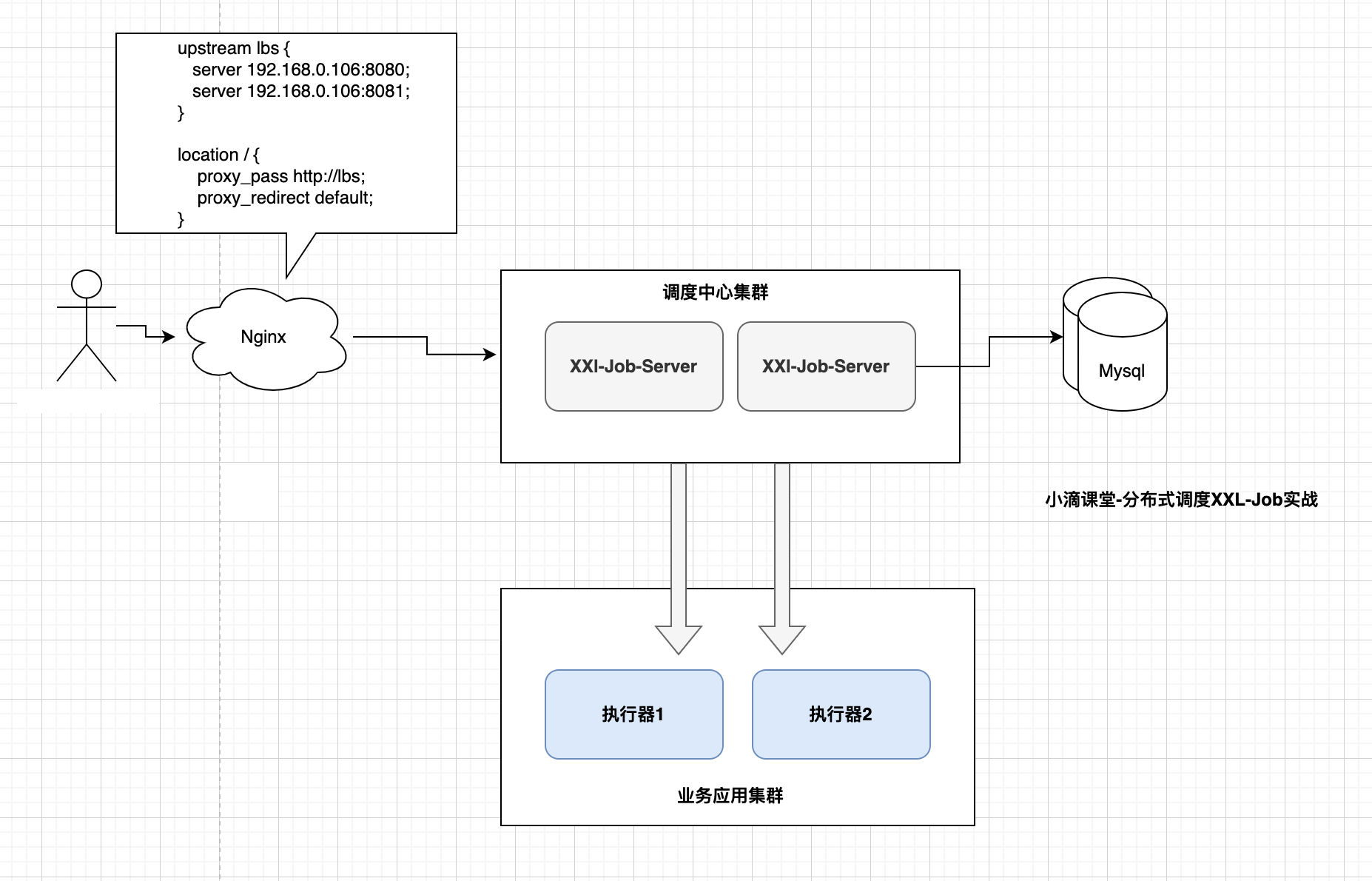
启动两个调度中心
分别是8080、8081
执行器配置
# 调度中心部署地址,多个配置逗号分隔 "http://address01,http://address02"
xxl.job.admin.addresses=http://192.168.10.88:8080/xxl-job-admin,http://192.168.10.88:8081/xxl-job-admin
海量数据处理:分片任务
背景需求
案例:双十一大促,给100万用户发营销短信
- 有一个任务需要处理100W条数据,每条数据的业务逻辑处理要0.1s
- 对于普通任务来说,只有一个线程来处理 可能需要10万秒才能处理完,业务则严重受影响
什么是分片任务
- 执行器集群部署,如果任务的路由策略选择【分片广播】,一次任务调度将会【广播触发】对应集群中所有执行器执行一次任务,同时系统自动传递分片参数,执行器可根据分片参数开发分片任务
- 需要处理的海量数据,以执行器为划分,每个执行器分配一定的任务数,并行执行
- XXL-Job支持动态扩容执行器集群,从而动态增加分片数量,到达更快处理任务
- 分片的值是调度中心分配的
// 当前分片数,从0开始,即执行器的序号
int shardIndex = XxlJobHelper.getShardIndex();
// 总分片数,执行器集群总机器数量
int shardTotal = XxlJobHelper.getShardTotal();
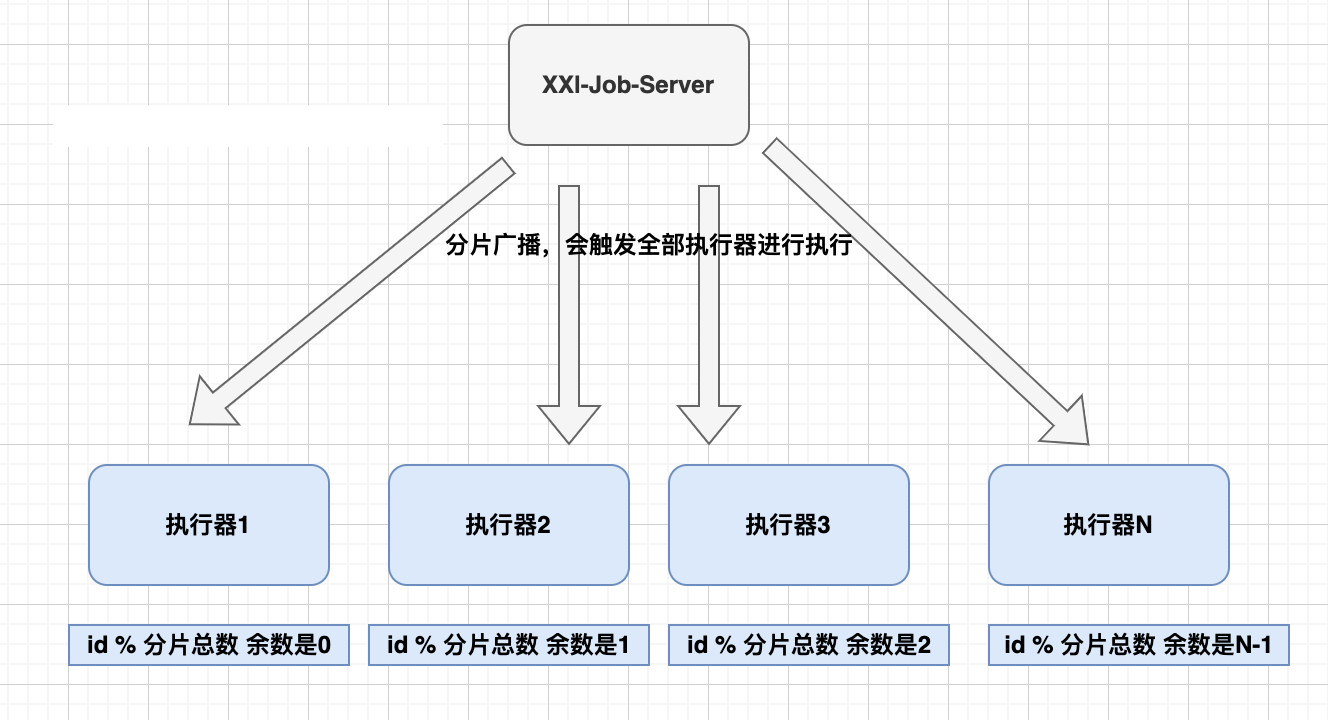
解决思路
- 如果将100W数据均匀分给集群里的10台机器同时处理
- 每台机器耗时,1万秒即可,耗时会大大缩短,也能充分利用集群资源
- 在xxl-job里,可以配置执行器集群有10个机器,那么分片总数是10,分片序号0~9 分别对应那10台机器。
- 分片方式
- id % 分片总数 余数是0 的,在第1个执行器上执行
- id % 分片总数 余数是1 的,在第2个执行器上执行
- id % 分片总数 余数是2 的,在第3个执行器上执行
- ...
- id % 分片总数 余数是9 的,在第10个执行器上执行
编码实战
需求:100个用户,分片处理
执行器编码
package net.xdclass.xdclassjob.job;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.context.XxlJobHelper;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
@Component
public class MyJobHandler {
/**
* 模拟获取数据库中的所有用户
* @return
*/
private List<Integer> getAllUserIds() {
ArrayList<Integer> ids = new ArrayList<>();
for (int i = 0; i < 100; i++) {
ids.add(i);
}
return ids;
}
/**
* 分片任务
*/
@XxlJob(value = "shardingJobHandler")
public void shardingJobHandler() {
//拿到当前执行器编号
int shardIndex = XxlJobHelper.getShardIndex();
//总的分片数(执行器的数量)
int shardTotal = XxlJobHelper.getShardTotal();
log.info("分片总数:{},当前分片数{}", shardTotal, shardIndex);
//只处理自身相关的任务
getAllUserIds().forEach(obj -> {
if (obj % shardTotal == shardIndex) {
log.info("第{}片,命中分片开始处理用户id={}", shardIndex, obj);
}
});
}
}
调度中心配置
1. **http://192.168.10.88:9997/**
2. **http://192.168.10.88:9998/**
3. **http://192.168.10.88:9999/**

控制台输出
### 执行器0
15:19:26.925 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 分片总数:3,当前分片数0
15:19:26.925 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第0片,命中分片开始处理用户id=0
15:19:26.925 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第0片,命中分片开始处理用户id=3
15:19:26.926 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第0片,命中分片开始处理用户id=6
……
### 执行器1
15:19:26.933 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 分片总数:3,当前分片数1
15:19:26.933 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第1片,命中分片开始处理用户id=1
15:19:26.934 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第1片,命中分片开始处理用户id=4
15:19:26.934 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第1片,命中分片开始处理用户id=7
……
### 执行器2
15:19:26.941 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 分片总数:3,当前分片数2
15:19:26.942 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第2片,命中分片开始处理用户id=2
15:19:26.942 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第2片,命中分片开始处理用户id=5
15:19:26.942 logback [Thread-6] INFO n.x.xdclassjob.job.MyJobHandler - 第2片,命中分片开始处理用户id=8
……