
Netty 背景与领域知识
Netty 背景
Netty 由 Trustin Lee (韩国、Line 公司) 2004 年开发。
* 本质:网络应用程序框架
* 实现:异步、事件驱动
* 特性:高性能、可维护、快速开发
* 用于:开发服务器和客户端
为什么不直接使用 JDK NIO
直接使用 JDK NIO = 一个人在战斗。
Netty 做的更多
* 支持常用应用层协议。
* 解决传输问题:粘包、半包现象。
* 支持流量整形。
* 完善的断连、Idle 等异常处理等。
Netty 做的更好
* 规避 JDK NIO bug: epoll bug (异常唤醒空转导致 CPU 100%) JDK NIO 2.4 版本。
* API 更优化、更强大。
* 隔离变化、屏蔽细节。
* 直接用 JDK 实现,代码量太多、BUG 也多。
* Netty 已经维护了 15 年。
网络通信框架对比
Netty 没有竞争对手。
* Apache Mina (Trustin Lee 背书 Netty)
* Sun Grizzly (用的少、文档少、更新少)
* Apple Swift NIO、ACE 等 (其他语言、Java 不考虑)
* Cindy 等 (生命周期短,淘汰很快)
* Tomcat、Jetty (还没有独立出来,没有通用性)
Netty 的发展历史
归属组织
* JBoss (4.0 之前)
* Netty (4.0 之后)
版本演变
* 2004 年 6 月 Netty2 发布 (声称 Java 社区中第一个基于事件驱动的应用网络框架)
* 2008 年 10 月 Netty3 发布
* 2013 年 7 月 Netty4 发布
* 2013 年 12 月发布 5.0.0.Alphal
* 2015 年 11 月废弃 5.0.0 (复杂、没有证明拥有明显性能优势、维护不过来)
Netty 与 Apache Mina 的关系
Alex 为 Apache Directory 开发网络框架,但是觉得不好用,看到 Netty2 后 找到作者(Trustin Lee),邀请合作开发结合两种框架,随后有了 Mina。
* 2004 年 6 月 Netty2 发布
* 2005 年 5 月 Mina 发布
Netty 现状与趋势
社区现状
维护者:22 members (core: Trustin Lee and Norman Maurer (德国人))
主要维护的分支:
* 4.1 master (16 年 5 月创建) :支持 Android
* 4.0 (13 年 7 月创建,最后一个提交在 2018 年) :线程模型优化、包结构、命名
应用现状:截至 2019 年 9 月, 30000+ 项目在使用。(根据 pom.xml 是否依赖作为是否使用的标准)
* 数据库:Cassandra
* 大数据处理: Spark、Hadoop
* MQ:RocketMQ
* 检索:Elasticsearch
* 框架:gRPC、Apache Dubbo、Spring5(WebFlux)
* 分布式协调器:Zookeeper
* 工具类:asyn-http-client
* 其他参考:https://netty.io/wiki/adopters.html
Netty 趋势:
* 更多流行协议的支持
* 紧跟 JDK 新功能步伐
* 更多易用、人性化的功能: IP 地址黑白名单、流量整型等…
* 应用越来越多
Java1.4 之前不支持异步 I/O
在 Java1.4 之前,由于对 I/O 支持并不完善,开发人员在开发高性能 I/O 程序的时候会面临一些巨大的挑战和困难,在 Java 支持异步 I/O 之前的很长一段时间里,高性能服务端开发领域一直被 C++ 和 C 长期占据,Java 的同步阻塞 I/O 被大家所诟病。
- 没有数据缓冲期,I/O 性能存在问题。
- 没有 Channel 概念,只有输入和输出流。
- 同步阻塞式 I/O 通信(BIO),通常会导致通信线程被长时间阻塞。
- 支持的字符集有限,硬件可以移植性不好。
Linux 网络 I/O 模型简介
Linux 的内核将所有外部设备都看作一个文件来操作,对一个文件的读写操作会调用内核提供的系统命令,返回一个 file descriptor(fd,文件描述符)。而对一个 socket 的读写也会有相应的描述符,被称为 socketfd(socket 描述符),描述符就是一个数字,它指向内核中的一个结构体(文件路径,数据区等一些属性)。
根据 UNIX 网络编程对 I/O 模型的分类,UNIX 提供了 5 种 I/O 模型,分别如下。
阻塞 I/O 模型
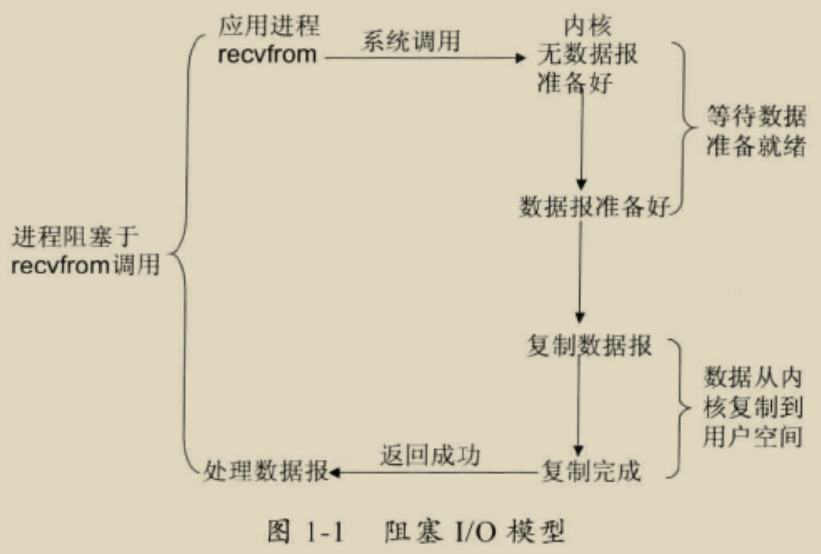
在用户空间中调用 recvfrom 之后,其系统调用知道数据包到达且被复制到进程的缓冲区中或者发生错误时才返回,在此期间一直会等待,进程在从调用 recvfrom 开始到它返回的这段时间内都是被阻塞的,因此被称为阻塞 I/O 模型。
非阻塞 I/O 模型
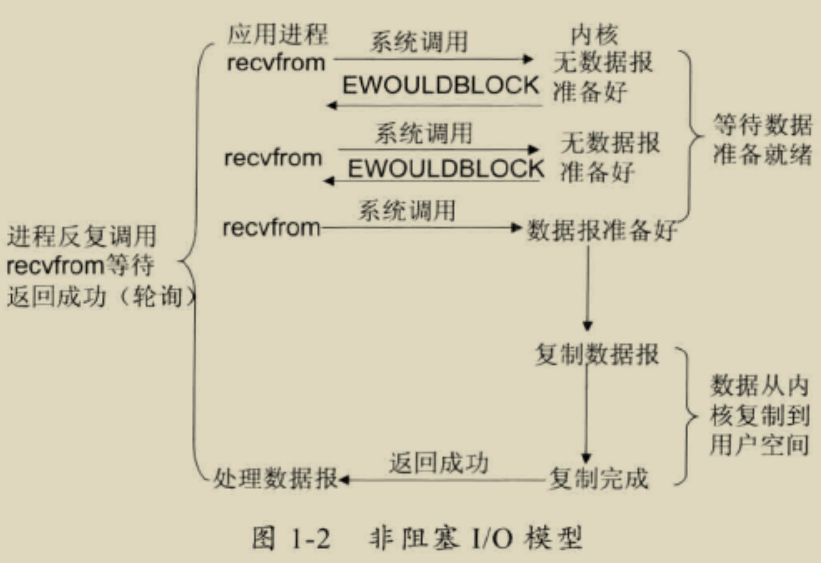
recvfrom 从用户空间到内核的时候,如果该缓冲区没有数据的话,就直接返回一个 EWOULDBLOCK 错误,一般都对非阻塞 I/O 模型进行轮询检查这个状态,看内核是不是有数据到来。
I/O 复用模型
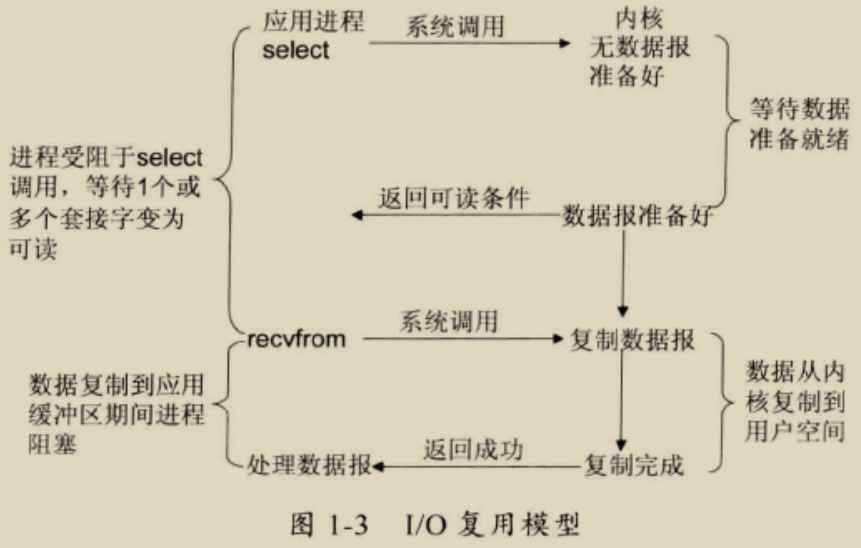
Linux 提供 select/poll,进程通过将一个或多个 fd 传递给 select 或 poll 系统调用,阻塞在 select 操作上,这样 select/poll 可以帮助我们侦测多个 fd 是否处于就绪状态。 select/poll 是顺序扫描 fd 是否就绪,而且支持的 fd 数量有限,因此它的使用受到了一些制约。Linux 还提供了一个 epoll 系统调用,epoll 使用基于事件驱动方式代替顺序扫描,因此性能更高。当有 fd 就绪时,立即调用函数 rollback。
信号驱动 I/O 模型
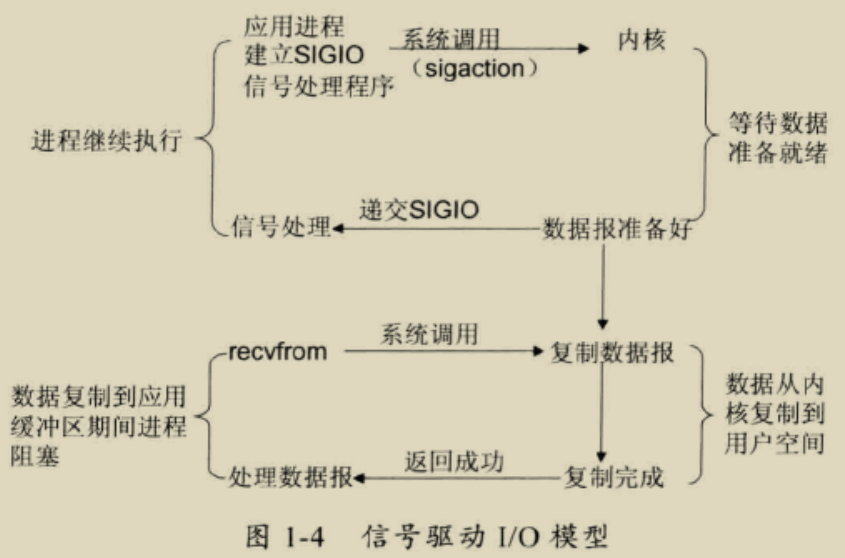
首先开启套接口信号驱动 I/O 功能,并通过系统调用 sigaction 执行一个信号处理函数(此系统调用立即返回,进程继续工作,它是非阻塞的)。当数据准备就绪时,就为该进程生成一个 SIGIO 信号,通过信号回调通知应用程序调用 recvfrom 来读取数据,并通知主循环函数处理数据。
异步 I/O
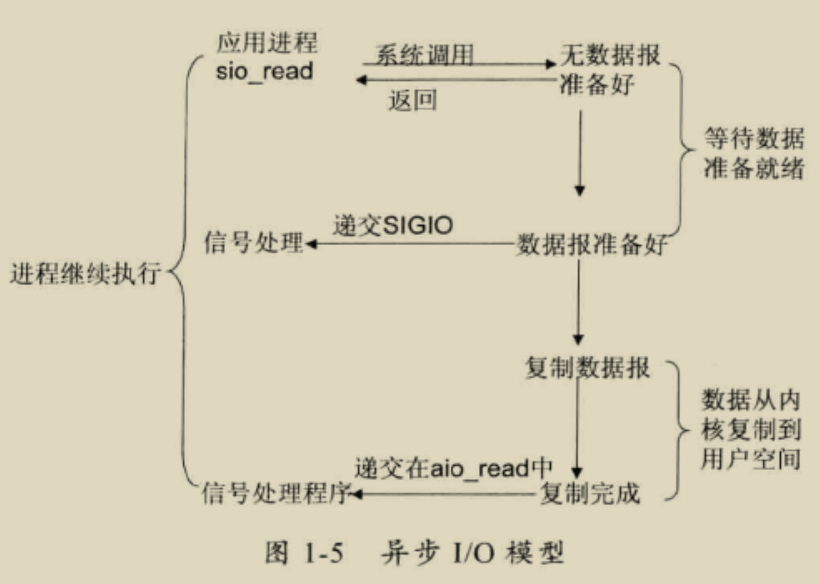
告知内核启动某个操作,并让内核在整个操作完成后(包括将数据从内核复制到用户自己的缓冲区)通知我们。这种模型与信号驱动模型的主要区别是:信号模型 I/O 有内核通知我们何时可以开始一个 I/O 操作;异步 I/O 模型有内核通知我们 I/O 操作何时已经完成。
I/O 多路复用技术
在 I/O 编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者 I/O 多路复用技术进行处理。I/O 多路复用技术通过把多个 I/O 的阻塞复用到同一个 select 的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O 多路复用的最大优势是系统开销效小,系统不需要创建新的额外进程或线程,也不需要维护这些进程和线程的运行,降低系统的维护工作量,节省了系统资源,I/O 多路复用的主要应用场景如下。
- 服务需要同时处理多个处于监听状态或者多个连接状态的套接字。
- 服务器需要同时处理多种网络协议的套接字。
目前支持 I/O 多路复用的系统调用有 select、pselect、poll、epoll,在 Linux 网络编程过程中,很长一段时间都使用 select 做轮询和网络事件通知,然而 select 的一些固有缺陷导致了他的应用受到了很大的限制,最终 Linux 不得不在新的内核版本中寻找 select 的替代方案,最终选择了 epoll。epoll 和 select 的原理比较类似,为了克服 select 的缺点,epoll 做了很多重大改进,总结如下。
- 支持一个进程打开的 socket 描述符(DF)不受限制(仅受限于操作系统的最大文件句柄数):select 最大的缺点就是单个进程所打开的 DF 是有一定限制的,它由 FD_SETSIZE 设置,默认值是 1024。对于那些需要支持上万个 TCP 连接的大型服务器来说显然太少了。可以选择修改这个宏然后重新编译内核,不过这会带来网络效率的下降。也可以通过选择多进程的方案解决这个问题,不过虽在在 Linux 创建进程的代价比较小,但仍旧不可忽视。另外进程间的数据交换非常麻烦,这对 Java 来说,由于没有共享内存,需要通过 Socket 通信或者其他方式进行数据同步,这带来了额外的性能损耗,增加了程序复杂度,所以也不是一种完美的解决方案。而 epoll 并没有这个限制,他锁支持的 FD 上限是操作系统的最大文件句柄数,这个数字远远大于 1024,例如:在 1GB 的内存机器上大约是 10 万个句柄左右,具体的值可以通过 cat /proc/sys/fs/file-max 察看,通常情况下这个值跟系统的内存关系比较大。
- I/O 效率不会随着 FD 数目的增加而线性下降:传统的 select/poll 的另一个致命缺点,就是当你拥有很大的 socket 集合时,由于网络延迟或者链路空闲,任一时刻只有少部分 socket 是"活跃"的,但是 select/poll 每次调用都会线性扫描全部的集合,导致效率呈现线性的下降。epoll 不存在这个问题,它只会对"活跃"的 socket 进行操作——这是因为在内核实现中,epoll 是根据每个 fd 上面的 callback 函数实现的。那么,只有"活跃"的 socket 才会去主动调用 callback 函数,其他 idle 状态的 socket 则不会。在这点上,epoll 实现了一个伪 AIO。针对 epoll 和 select 性能对比的 benchmark 测试表面:如果所有 socket 都处于活跃状态——例如一个高速 LAN 环境,epoll 并不比 select/poll 效率高太多;相反,如果过多的使用 epoll_ctl,效率相比还有稍微地降低。但是一旦使用 idle connections 模拟 WAN,epoll 的效率就远在 select/poll 之上。
- 使用 mmap 加速内核与用户空间的消息传递:无论是 select、poll 还是 epoll 都需要内核把 FD 消息通知给用户空间,如何避免不必要的内存复制就显得非常重要了,epoll 是通过内核和用户空间 mmap 同一块内存来实现的。
- epoll 的 API 更加简单:包括创建一个 epoll 描述符、添加监听事件、阻塞等待所有监听的时间发生、关闭 epoll 描述符等。
Java 的 I/O 演进史
在 JDK1.4 退出 Java NIO 之前,基于 Java 的所有 Socket 通信都采用了同步阻塞模式(BIO),这种一请求一应答的通信模型简化了上层的应用开发,但是在性能和可靠性方面却存在着巨大的瓶颈。因而在很长一段时间里,大型的应用服务器都采用 C 或者 C++ 语言开发,因为它们可以执行使用操作系统提供的异步 I/O 或者 AIO 能力。当并发访问量增大、响应时间延迟增大之后,采用 Java BIO 开发的服务器端软件只有通过硬件的不断扩容来满足高并发和低延迟,它极大地增加了企业的成本,并且随着集群规模的不断膨胀,系统的可维护性也面临巨大的挑战。
正是由于 Java 传统 BIO 的拙劣表现,才使得 Java 支持非阻塞 I/O 的呼声日渐高涨,最终,JDK1.4 版本您提供了新的 NIO 类库,Jaav 终于可以支持非阻塞 I/O 了。
传统的 BIO 编程模型
网络编程的基本模型是 Client/Server 模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息(绑定的额 IP 地址和监听的端口),客户端通过连接操作向服务端监听的地址发起连接请求,通过三次握手建立连接,如果连接建立成功,双方就可以通过网络套接字(Socket)进行通信。
在基于传统同步阻塞模型开发中,ServerSocket 负责绑定 IP 地址,启动监听端口;Socket 负责发起连接操作。连接成功之后,双发通过输入和输出流进行同步阻塞式的通信。
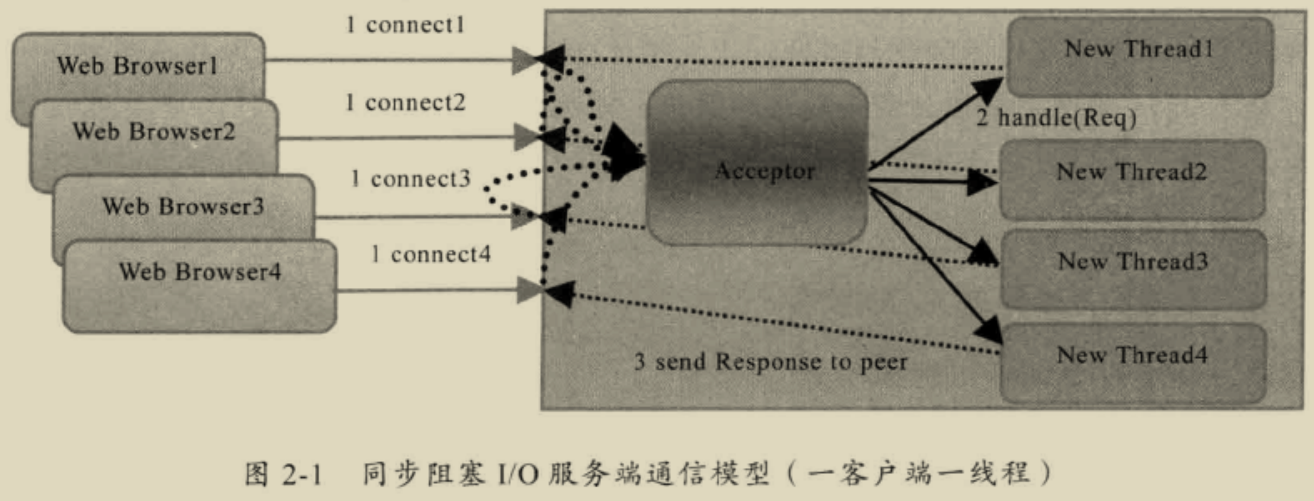
模型简单、编码简单。
该模型最大的问题就是缺乏弹性伸缩能力,当客户端并发访问量增加后,服务端的线程个数和客户端的并发访问数呈 1:1 的正比关系,由于线程是 Java 虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统的性能将急剧下降,随着并发访问量的继续增大,系统会发生线程堆栈溢出、创建新线程失败等问题,并最终导致进程宕机或者僵死,不能对外提供服务。
Web 服务器 Tomcat7 之前,都是使用 BIO,7 之后就使用 NIO。改进:伪 NIO,使用线程池去处理业务逻辑。
BioServer
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
public class BioServer {
private static final int PORT = 8080;
public static void main(String[] args)throws IOException {
ServerSocket server = null;
try {
server = new ServerSocket(PORT);
System.out.println("the time server is start in port :"+PORT);
Socket socket = null;
while (true){
//循环监听客户端发起的连接请求
socket = server.accept();
new Thread(new TimeServerHandler(socket)).start();
//线程池 总共 1000 个请求,线程池数量 100,等待队列 500(BlockingQueue),还有 400 个请求
//一般高并发访问的时候,比如大学抢课,会出现拒绝链接,或者链接超时
//ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor()
}
}catch (Exception e){
e.printStackTrace();
}finally {
if(server != null){
System.out.println("the time server close");
server.close();
}
}
}
}
BioClient
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket;
public class BioClient {
private static final int PORT = 8080;
private static final String HOST = "127.0.0.1";
public static void main(String[] args)throws IOException {
Socket socket = null;
BufferedReader in = null;
PrintWriter out = null;
try {
socket = new Socket(HOST, PORT);
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(socket.getOutputStream(), true);
out.println("i am client");
String resp = in.readLine();
System.out.println("当前服务器时间是:"+resp);
}catch (Exception e){
e.printStackTrace();
}finally {
if (in != null) {
try {
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (out != null) {
try {
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (socket != null) {
try {
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
TimeServerHandler(业务逻辑类)
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket;
import java.util.Date;
public class TimeServerHandler implements Runnable{
private Socket socket;
public TimeServerHandler(Socket socket){
this.socket = socket;
}
@Override
public void run() {
//输入流
BufferedReader in = null;
//输出流
PrintWriter out = null;
try {
in = new BufferedReader( new InputStreamReader(this.socket.getInputStream()));
out = new PrintWriter(this.socket.getOutputStream(),true);
String body = null;
while (( body = in.readLine())!= null && body.length()!=0){
//读取
System.out.println("the time server receive msg :"+body);
//写入
out.println(new Date().toString());
}
} catch (Exception e){
e.printStackTrace();
} finally {
if(in != null){
try {
in.close();
}catch (Exception e){
e.printStackTrace();
}
}
if(out != null){
try {
out.close();
}catch (Exception e){
e.printStackTrace();
}
}
if(this.socket != null){
try{
this.socket.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
}
}
curl 测试
# curl 测试命令
C:\Users\soulboy>curl localhost:8080
Tue Sep 24 15:50:33 CST 2019
Tue Sep 24 15:50:33 CST 2019
Tue Sep 24 15:50:33 CST 2019
Tue Sep 24 15:50:33 CST 2019
# BioServer
the time server is start in port :8080
the time server receive msg :GET / HTTP/1.1
the time server receive msg :Host: localhost:8080
the time server receive msg :User-Agent: curl/7.55.1
the time server receive msg :Accept: */*
the time server receive msg :i am client
the time server receive msg :i am client
the time server receive msg :i am client
# BioClient
当前服务器时间是:Tue Sep 24 16:00:40 CST 2019
伪异步 I/O 编程模型
为了解决同步阻塞 I/O 面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行优化——后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数 M:线程池最大线程数 N 的比例关系,其中 M 可以远远大于 N。通过线程池可以灵活地调配线程资源,设置线程的最大值,可以有效的防止由于海量并发接入导致线程耗尽。但由于底层采用的依然是 BIO,当对 Socket 的输入流进行读取操作时候,它会一直阻塞下去,知道发生如下三种事件:
- 有数据可读取;
- 可用数据已经读取完毕;
- 发生空指针或者 I/O 异常。
这意味着当对方发送请求或者应答消息比较缓慢,或者网络传输较慢时,读取输入流一方的线程将长时间阻塞,如果对方要 60s 才能够将数据发送完成,读取一方的 I/O 线程也将会被阻塞 60s,在此期间,其他接入消息只能在消息队列中排队。
当调用 OutputStream 的 write 方法写输出流的时候,它将会被阻塞,直到所有要发送的字节全部写入完毕,或者发生异常。
通过对输入和输出流的 API 文档进行分析,发现读和写操作都是同步阻塞的,阻塞的时间取决于对方 I/O 线程的处理速度和网络 I/O 的传输速度。本质上来讲,我们无法保证生产环境网络状况和对端的应用程序能足够快的响应,如果我们的应用程序依赖于对方的处理速度,它的可靠性就非常差。因此伪异步 I/O 实际上仅仅是对之前 I/O 线程模型的一个简单的优化,它无法从根本上解决同步 I/O 导致的通信线程阻塞问题。
NIO 编程模型
Non-block I/O,与 Socket 类和 ServerSocket 类相对应,NIO 也提供了 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,这两种新增的通道都支持阻塞和非阻塞两种模式。一般来说,低负载、低并发的应用程序可以选择同步阻塞 I/O 以降低编程复杂度;对于高负载、高并发的网络应用,需要使用 NIO 的非阻塞模式进行开发。
NIO 编程中的基本概念
- 缓冲区 Buffer:NIO 中,所有数据都是用缓冲区处理,任何时候访问 NIO 中的数据,都是通过缓冲区进行操作。
- 通过到 Channel:通道可以用于读、写或者二者同时进行。
- 多路复用器 Selector:多路复用器提供选择已经就绪任务的能力。Selector 会不断轮询注册在其上的 Channel,如果某个 Channel 上面发生读或写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来,然后通过 SelectionKey 可以获取就绪 Channel 的集合,进行后续的 I/O 操作。JDK 使用 epoll()代替传统的 select 实现,所以他并没有最大连接句柄 1024/2048 的限制,这也意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。

NIO 的优点
- 客户端发起的连接操作是异步的,可以通过在多路复用器注册 OP_CONNECT 等地啊后续结果,不需要像之前的客户端那样被同步阻塞。
- SocketChannel 的读写操作都是异步的,如果没有可读写的数据它不会同步等待,直接返回,这样 I/O 通信线程就可以处理其他的链路,不需要同步等待这个链接可用。
- 线程模型的优化:JDK 的 Selector 在 Linux 等主流操作系统上通过 epoll 实现,一个 Selector 线程可以同时处理成千上万个客户端连接,而性能不会随着客户端的增加而线性下降,因此,它非常适合做高性能、高负载的网络服务器。
AIO 编程模型
JDK1.7 升级了 NIO 类库,升级后的 NIO 类库成为 NIO2.0。Java 正式提供了异步文件 I/O 操作,同时提供了与 UNIX 网络编程事件驱动 I/O 对应的 AIO。
Linux 网络编程中的五种 I/O 的模型
阻塞与非阻塞:发起请求之后,数据准备完毕之前的状态。 第一段
同步与异步:数据准备好之后,请求的发起者是否参与。 第二段
前四种都是同步 IO,在内核数据 copy 到用户空间时都是阻塞的(晾衣服)。
- 阻塞式 I/O:(两段式阻塞)
- 非阻塞式 I/O:(阻塞在第二段,内核空间数据复制到用户空间数据需要发起者参与 IO 操作)
- I/O 复用:select,poll,epoll...(阻塞在第二段,内核空间数据复制到用户空间数据需要发起者参与 IO 操作) 少量线程响应多个请求(仅此提升而已)。
# I/O 多路复用是
第一段阻塞在 select,epoll 这样的系统调用,而没有阻塞在真正的 I/O 系统调用如 recvfrom。等待可能多个套接口中的任一个变为可读时,通知受阻塞进程进入第二段,并使用 recvfrom 进行系统调用。
# Blocking I/O 与 I/O 多路复用的区别
IO 多路复用使用两个系统调用(select 和 recvfrom),第一段使用 select,第二段使用 recvfrom.
blocking IO 只调用了一个系统调用(recvfrom),两端均使用 recvfrom
# IO 多路复用与非阻塞 I/O 相比的进步
elect/epoll 核心是以尽可能少的线程同时处理多个 connection,而不是执行速度更快。
在连接数不高的情况下,性能不一定比多线程 + 阻塞 I/O 好。
多路复用模型中,每一个 socket,设置为 non-blocking,阻塞在 select 这个函数,而不是阻塞在 socket 上。
- 信号驱动式 I/O(SIGIO):几乎不用。
# 与多路复用的区别
在第一段从扫描接口变为数据报准备好之后自动通知。在第一段中比扫描接口的开销要小。
- 异步 I/O(POSIX 的 aio_系列函数) Future-Listener 机制:第二段中自动复制完毕数据到用户空间,通知调用者。
IO 操作分为两段式
- 发起 IO 请求,等待数据准备(Waiting for the data to be ready)
- 实际的 IO 操作,将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
五种 IO 模型的区别
前四种 IO 模型都是同步 IO 操作,区别在于第一阶段,
而他们的第二阶段是一样的:在数据从内核复制到应用缓冲区期间(用户空间),进程阻塞于 recvfrom 调用或者 select()函数。
相反,异步 I/O 模型在这两个阶段都不需要参与 I/O 处理。
阻塞和非阻塞
发起 IO 请求是否会被阻塞,如果阻塞直到完成那么就是传统的阻塞 IO,如果不阻塞,那么就是非阻塞 IO。
同步 IO 和异步 IO 的区别
如果实际的 IO 读写阻塞请求进程,那么就是同步 IO
因此阻塞 IO、非阻塞 IO、IO 复用、信号驱动 IO 都是同步 IO,
如果不阻塞,而是操作系统帮你做完 IO 操作再将结果返回给你,那么就是异步 IO。
IO 多路复用
I/O 多路复用,I/O 是指网络 I/O, 多路指多个 TCP 连接(即 socket 或者 channel),复用指复用一个或几个线程。
简单来说:就是使用一个或者几个线程处理多个 TCP 连接
优先:最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程
JavaI/O 演进历史
JDK1.4 之前
采用同步阻塞模型,也就是 BIO。
JDK1.4
NIO,支持非阻塞 IO。
JDK1.7
推出 NIO2.0,提供 AIO 的功能,支持文件和网络套接字的异步 IO。NIO2.0 才可以被称作真正的 AIO。
Java 原生 NIO 编程的复杂度
除非你精通 NIO 编程或者有特殊的需求,否则在绝大数场景下都不应该直接使用 JDK 的 NIO 类库。
- NIO 的类库和 API 繁杂,使用麻烦,需要熟练掌握 Selector、ServerSocketChannel、SocketChannel、ByteBuffer 等。
- 需要具备其他的额外技能做铺垫,例如:熟悉 Java 多线程,这是因为 NIO 编程设计到了 Reactor 模式,所以必须对多线程和网络编程非常熟悉,才能编程出高质量的 NIO 程序。
- 可靠性能力不补齐、工作和难度都非常大。例如:客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等问题,NIO 编程的特点是功能开发相对容易,但是可靠性能力补齐的工作量和难度都非常大。
- JDK NIO 的 BUG。
Netty 线程模型和 Reactor 模式
设计模式——Reactor 模式(反应器设计模式),是一种基于事件驱动的设计模式,在事件驱动的应用中,将一个或多个客户的服务请求分离(demultiplex)和调度(dispatch)给应用程序。在事件驱动的应用中,同步地、有序地处理同时接收的多个服务请求。
一般出现在高并发系统中,比如 Netty,Redis 等
Reactor 模式基于事件驱动,适合处理海量的 I/O 事件,属于同步非阻塞 IO(NIO)
优点
- 响应快,不会因为单个同步而阻塞,虽然 Reactor 本身依然是同步的;
- 编程相对简单,最大程度的避免复杂的多线程及同步问题,并且避免了多线程/进程的切换开销;
- 可扩展性,可以方便的通过增加 Reactor 实例个数来充分利用 CPU 资源;
缺点
- 相比传统的简单模型,Reactor 增加了一定的复杂性,因而有一定的门槛,并且不易于调试。
- Reactor 模式需要系统底层的的支持,比如 Java 中的 Selector 支持,操作系统的 select 系统调用支持
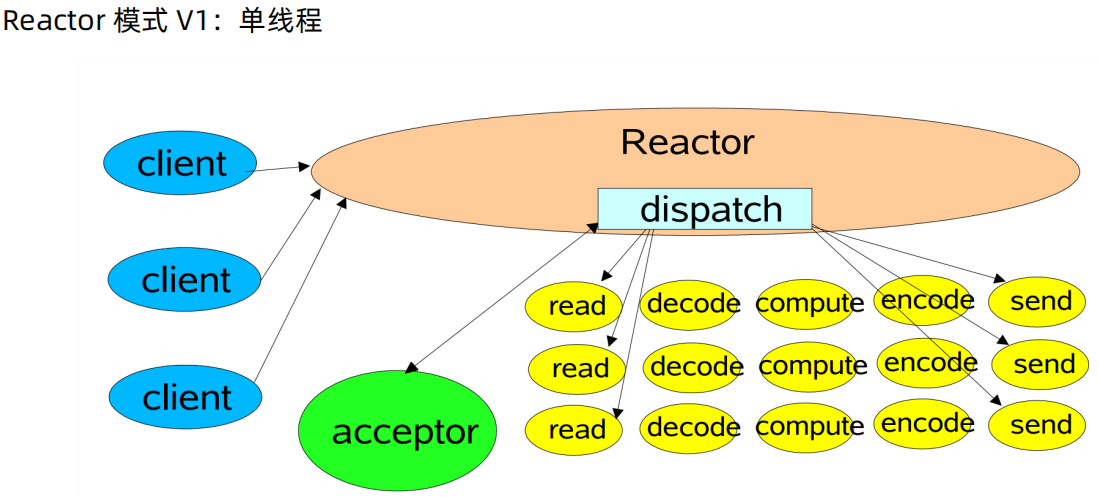
Reactor 单线程模型(比较少用)
作为 NIO 服务端,接收客户端的 TCP 连接;作为 NIO 客户端,向服务端发起 TCP 连接。
服务端读请求数据并响应;客户端写请求并读取响应。
对应小业务则适合,编码简单;对于高负载、大并发的应用场景不适合,一个 NIO 线程处理太多请求,则负载过高,并且可能响应变慢,导致大量请求超时,而且万一线程挂了,则不可用了。
Reactor 多线程模型
一个 Acceptor 线程,一组 NIO 线程,一般是使用自带的线程池,包含一个任务队列和多个可用的线程。
可满足大多数场景,但是当 Acceptor 需要做复杂操作的时候,比如认证等耗时操作,再高并发情况下则也会有性能问题。
Reactor 主从线程模型
Acceptor 不在是一个线程,而是一组 NIO 线程;IO 线程也是一组 NIO 线程,这样就是两个线程池去处理接入连接和处理 IO。
满足目前的大部分场景,也是 Netty 推荐使用的线程模型。BossGroup、WorkGroup。
为什么 Netty 不使用 BIO
连接数高的情况下:阻塞 -> 耗资源、效率低。
为什么 Netty 不使用 AIO
- Windows 实现成熟,但很少用来做服务器。
- Linux 的 aio_*系列的调用是 glibc 提供的,是 glibc 用多线程 + 阻塞调用来模拟的,性能很差。没有很好实现 AIO,因此在性能上没有明显的优势,而且被 JDK 封装了一层不容易深度优化
- Netty 整体架构是 reactor 模型, 而 AIO 是 proactor 模型, 混合在一起会非常混乱,把 AIO 也改造成 reactor 模型看起来是把 epoll 绕个弯又绕回来
- AIO 还有个缺点是接收数据需要预先分配缓存, 而不是 NIO 那种需要接收时才需要分配缓存, 所以对连接数量非常大但流量小的情况, 内存浪费很多
- Linux 上 AIO 不够成熟,处理回调结果速度跟不上处理需求,比如外卖员太少,顾客太多,供不应求,造成处理速度有瓶颈(待验证)
为什么 Netty 有多种 NIO 实现?
通用的 NIO 实现(Common)在 Linux 下也是使用 epoll,为什么要自己单独实现?
因为 Netty 做的更好。
* Netty 暴露了更多的可控参数:
JDK 的 NIO 默认实现是水平触发
Netty 是边缘触发(默认) 和 水平触发可切换
* Netty 实现的垃圾回收更少、性能更好
NIO 不一定优于 BIO
BIO
编码简单。
特定场景:连接数少,并发度低,BIO 性能不输 NIO。
Netty 对 IO 的支持
如果想要切换 Netty 底层的 IO,从默认的 NIO 切换到 BIO 可以做如下修改。
public final class EchoServer {
static final boolean SSL = System.getProperty("ssl") != null;
static final int PORT = Integer.parseInt(System.getProperty("port", "8007"));
public static void main(String[] args) throws Exception {
// Configure SSL.
final SslContext sslCtx;
if (SSL) {
SelfSignedCertificate ssc = new SelfSignedCertificate();
sslCtx = SslContextBuilder.forServer(ssc.certificate(), ssc.privateKey()).build();
} else {
sslCtx = null;
}
// Configure the server. (开发模式) : OioEventLoopGroup()
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
final EchoServerHandler serverHandler = new EchoServerHandler();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
// Configure the server. (IO 模式): OioServerSocketChannel.class
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 100)
.handler(new LoggingHandler(LogLevel.INFO))
//两种设置keepalive风格
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childOption(NioChannelOption.SO_KEEPALIVE, true)
//切换到unpooled的方式之一
.childOption(ChannelOption.ALLOCATOR, UnpooledByteBufAllocator.DEFAULT)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
if (sslCtx != null) {
p.addLast(sslCtx.newHandler(ch.alloc()));
}
p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});
// Start the server.
ChannelFuture f = b.bind(PORT).sync();
// Wait until the server socket is closed.
f.channel().closeFuture().sync();
} finally {
// Shut down all event loops to terminate all threads.
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
Netty 对 IO 的支持及 Reactor 的三种版本
三种 IO 对应的三种开发模式
NIO 下的开发模式是 Reactor。
| BIO | NIO | AIO |
|---|---|---|
| Thread-Per-Connection | Reactor | Proactor |
Reactor 简介
Reactor 是一种开发模式,模式的核心流程:注册感兴趣的事件 --> 扫描是否有感兴趣的事件发生 --> 事件发生后作出相应的处理

* 一人包揽所有:迎宾、点菜、做饭、上菜、送客等…
* 多招几个伙计:大家一起做上面的事情
* 进一步分工:让一个或多个人专门做迎宾

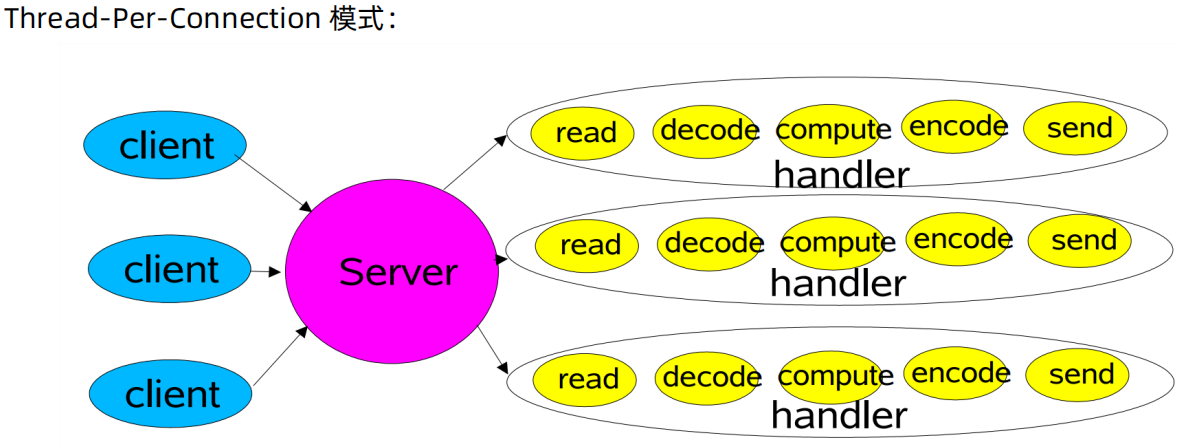
BIO(Thread-Per-Connection)
NIO(Reactor)
模式一:单线程
模式二:多线程

模式三:主从多线程

如何在 Netty 中使用 Reactor 模式

Netty 屏蔽 TCP 粘包、半包的复杂性
| send | receive | |
|---|---|---|
| 粘包 | ABC DEF | ABCDEF |
| 半包 | ABC DEF | AB CD EF |
粘包的主要原因
* sender 每次写入数据 < 套接字缓冲区大小
* receiver 读取套接字缓冲区数据不够及时
半包的主要原因
* sender 写入数据 > 套接字缓冲区大小
* sender 数据大于协议的 MTU(Maximum Transmission Unit,最大传输),必须拆包。
从收发和传输角度看
- 收发:一个发送可能被多次接收(半包),多个发送可能被一次接收(粘包)
- 传输:一个发送可能占用多个传输包(半包),多个发送可能公用一个传输包(粘包)。
根本原因
TCP 是流式协议,消息无边界。
Tips:UDP 像邮寄的包裹,虽然一次运输多个,但每个包裹都有 “界限”,一个一个签收,故不存在:粘包、半包问题。
解决问题的根本手段:找出消息的边界

Netty 对三种常用封侦方式的支持

常用的 “二次” 编解码方式
为什么需要 “二次” 编解码 ?
假设我们把解决粘包半包问题的常用三种解码器叫一次解码器。
那么我们在项目中,除了可选的压缩、解压缩之外,还需要一层解码,因为一次解码的结果是字节,需要和项目中所使用的对象做转化,方便使用,这层解码器可以成为 “二次解码器”,相应的,对应的“二次编码器”是为了将 Java 对象转化成字节流方便存储或传输。
# 一次解码器: ByteToMessageDecoder
io.netty.buffer.ByteBuf (原始数据流:粘包半包问题的字节数据) --> io.netty.buffer.ByteBuf(用户数据:不存在粘包半包问题的字节数据)
# 二次解码器: MessageToMessageDecoder<I>
io.netty.buffer.ByteBuf(用户数据:不存在粘包半包问题的字节数据) --> Java Object
常用的 “二次” 编解码方式
- 空间:编码后占用空间大小
- 时间:编解码速度
- 可读性
- 多语言的支持
* Java 序列化
* Marshaling
* XML
* JSON
* MessagePack
* Protobuf
* 其他
Google Protobuf 简介
- Protobuf 是一个灵活的、高效的用于序列化数据的协议。
- 相比较 XML 和 JSON 格式,Protobuf 更小、更快、更便捷。
- Protobuf 是跨语言的,并且自带了一个编译器(protoc),只需要用它进行编译,可以自动生成 Java、python、C++ 等代码,不需要再写其他代码。
keepalive 与 Idle 检测
为什么需要keepalive?
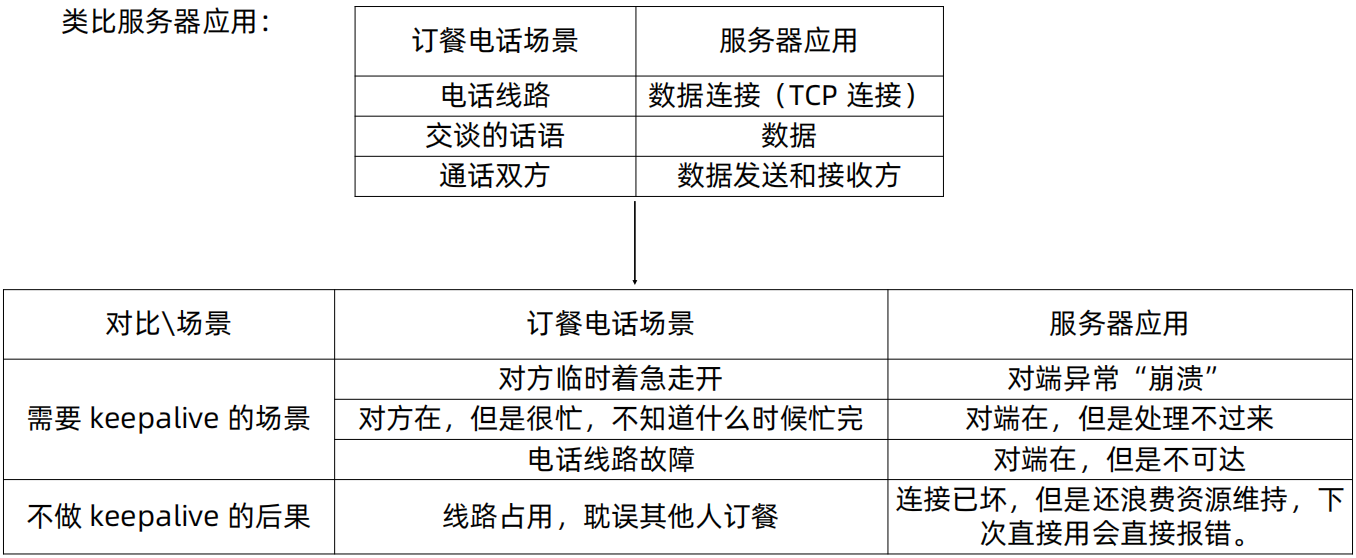
TCP keepalive 设计要点

为什么还需要应用层 keepalive?
各层关注点不同:传输层关注是否 “通”,应用层关注是否 “可服务”。
* keepalive 可能被丢弃:TCP 层的 keepalive 默认关闭,并且经过路由等中转设备 keepalive 包可能会被丢弃。
* 属于系统参数,改动影响所有应用:默认 > 2小时
应用层协议 HTTP 中的 HTTP Keep-Alive 指的是对长连接和短连接的选择:
* Connection: Keep-Alive 长连接(HTTP/1.1 默认长连接,不需要带这个 header)
* Connection: Close (短连接)
Idle 检测是什么?
Idle 监测,只是负责诊断,诊断后,做出不同的行为,决定 Idle 监测的最终用途:
- 一般用来配合 keepalive,减少 keepalive消息:很明显 V1 定时发送在大规模的时候发送的 keepalive 包数量会巨大。
# keepalive 演进
* V1 定时 keepalive 消息:keepalive 消息与服务器正常消息交换完全不关联,定时就发送。
* V2 空闲监测 + 判定为 Idle 时才发 keepalive。
- 直接关闭连接:按需 keepalive,保证不会空闲,如果空闲,关闭连接。
* 快速释放损坏的、恶意的、很久不用的连接,让系统时刻保持最好的状态。
* 简单粗暴,客户端可能需要重连。
如何在 Netty 中开启 TCP keepalive 和 Idle 检测
开启 keepalive
//Server 端开启 TCP keepalive
bootstrap.childOption(ChannelOption.SO_KEEPALIVE,true)
bootstrap.childOption(NioChannelOption.of(StandardSocketOptions.SO_KEEPALIVE), true)
提示:.option(ChannelOption.SO_KEEPALIVE,true) 存在但是无效
开启不同的 Idle Check:
ch.pipeline().addLast(“idleCheckHandler", new IdleStateHandler(0, 20, 0, TimeUnit.SECONDS));
Netty 如何使用锁
- 在意锁的对象和范围:减小粒度
- 注意锁的对象本身大小:减少空间占用
- 注意锁的速度:提高并发性
- 不同场景选择不同的并发包:因素而变
- 衡量好锁的价值:能不用则不用
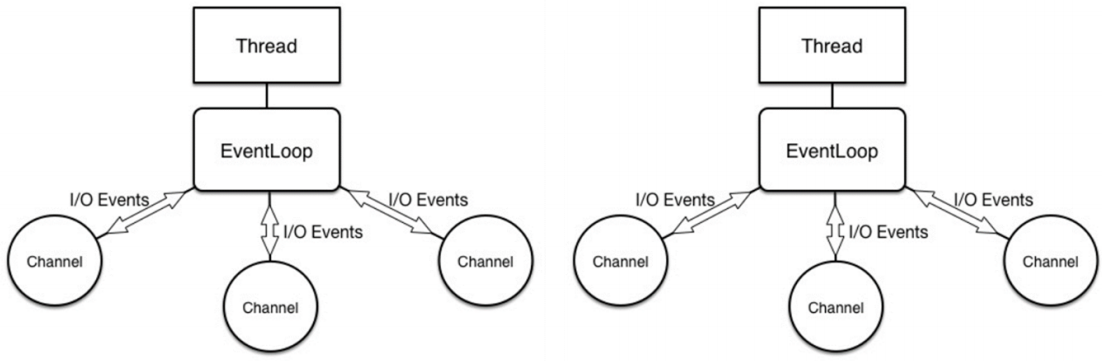
* 局部串行:Channel 的 I/O 请求处理 Pipeline 是串行的
* 整体并行:多个串行化的线程(NioEventLoop)
* Netty 应用场景下:局部串行 + 整体并行 > 一个队列 + 多个线程模式
降低用户开发难度、逻辑简单、提升处理性能
避免锁带来的上下文切换和并发保护等额外开销
- 局部串行

- 整体并行
Netty 如何玩转内存使用
目标:对于 Java 而言:减少Full GC 的 STW(Stop the world)时间。
* 内存占用少(空间)
* 应用速度快(时间)
Netty 内存使用技巧 - 减少对象本身大小
能用基本类型就不要用包装类.
能应该定义成类变量的不要定义为实例变量。
Netty 内存使用技巧 - 对分配内存进行预估
Netty 根据接受到的数据动态调整(guess)下个要分配的 Buffer 的大小。
Netty 内存使用技巧 - Zero-Copy
使用逻辑组合,代替实际复制。调用 JDK 的 Zero-Copy 接口。
Netty 内存使用技巧 - 堆外内存
# 什么是堆外内存
* 店内 -> JVM 内部 -> 堆(heap) + 非堆(non heap)
* 店外 -> JVM 外部 -> 堆外(off heap)
# 堆外内存的优点
* 更广阔的“空间 ”,缓解店铺内压力 -> 破除堆空间限制,减轻 GC 压力
* 减少“冗余”细节(假设烧烤过程为了气氛在室外进行:烤好直接上桌:vs 烤好还要进店内)-> 避免复制
# 堆外内存的缺点
* 需要搬桌子 -> 创建速度稍慢
* 受城管管、风险大 -> 堆外内存受操作系统管理
Netty 内存使用技巧 - 内存池
开源实现:Apache Commons Pool
Netty 轻量级对象池实现 io.netty.util.Recycler
* 创建对象开销大
* 对象高频率创建且可复用
* 支持并发又能保护系统
* 维护、共享有限的资源