
布隆过滤器
布隆过滤器简介
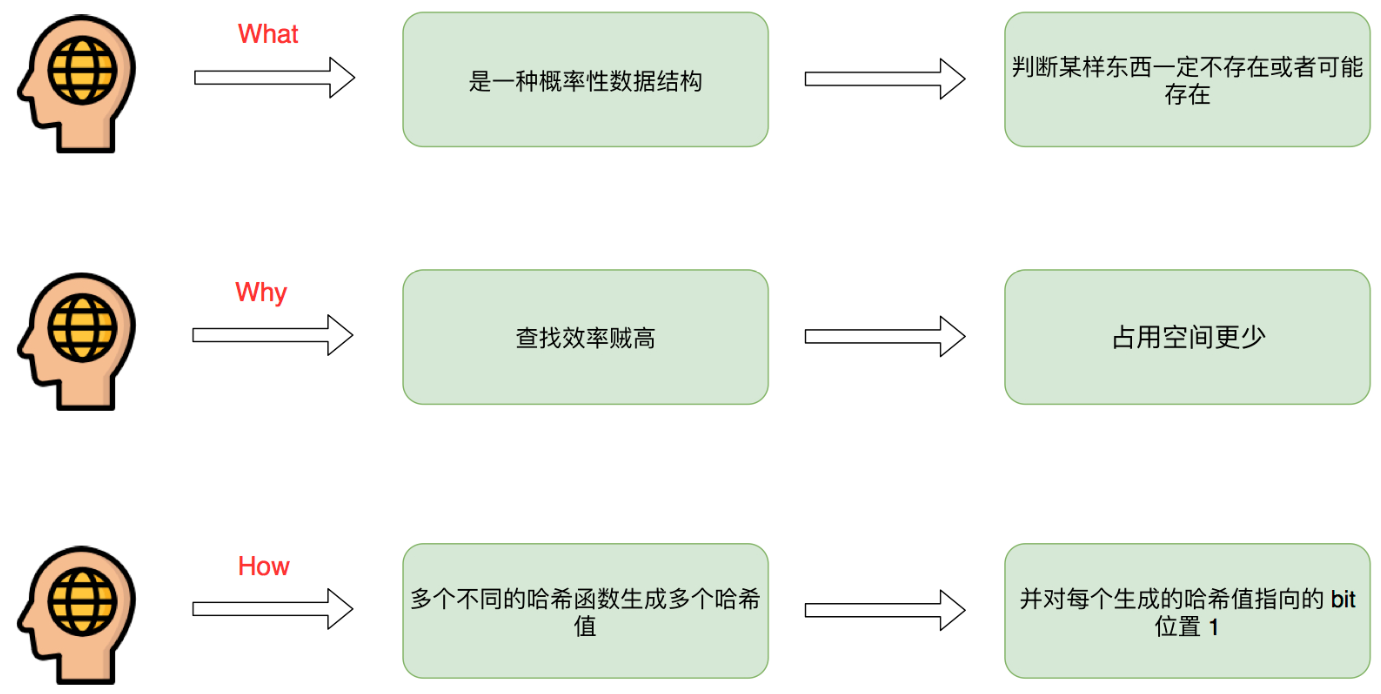
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数(即复杂度为 O(k))。另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
布隆过滤器的使用场景
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
- 网页爬虫对 URL 的去重,避免爬取相同的 URL 地址;
- 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信);
- 缓存穿透,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及 DB 挂掉。
布隆过滤器数据结构
布隆过滤器实现原理
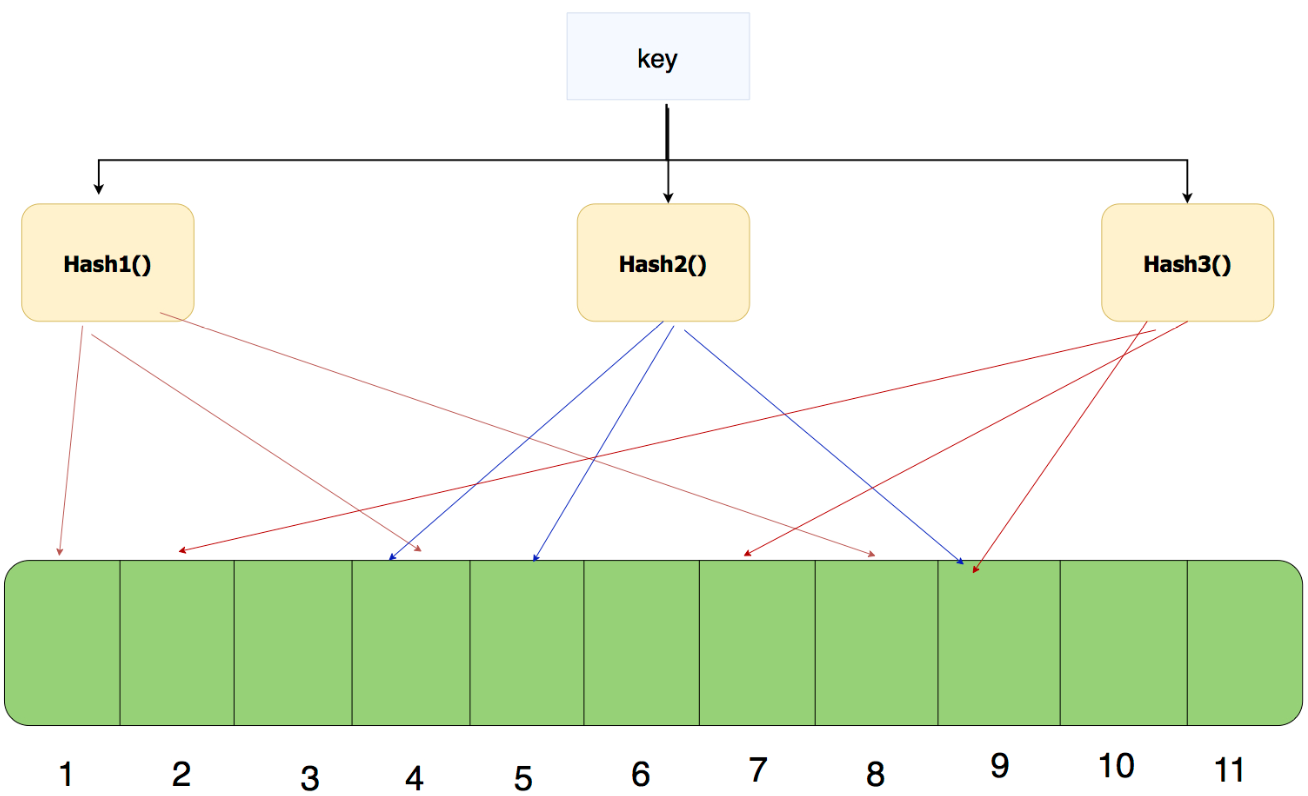
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都位 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
使用时不要让实际元素远大于初始化大小,当实际元素开始超出初始化大小时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进去 (这就要求我们在其它的存储器中记录所有的历史元素)。因为 error_rate 不会因为数量超出就急剧增加,这就给我们重建过滤器提供了较为宽松的时间。
布隆过滤器实抽奖
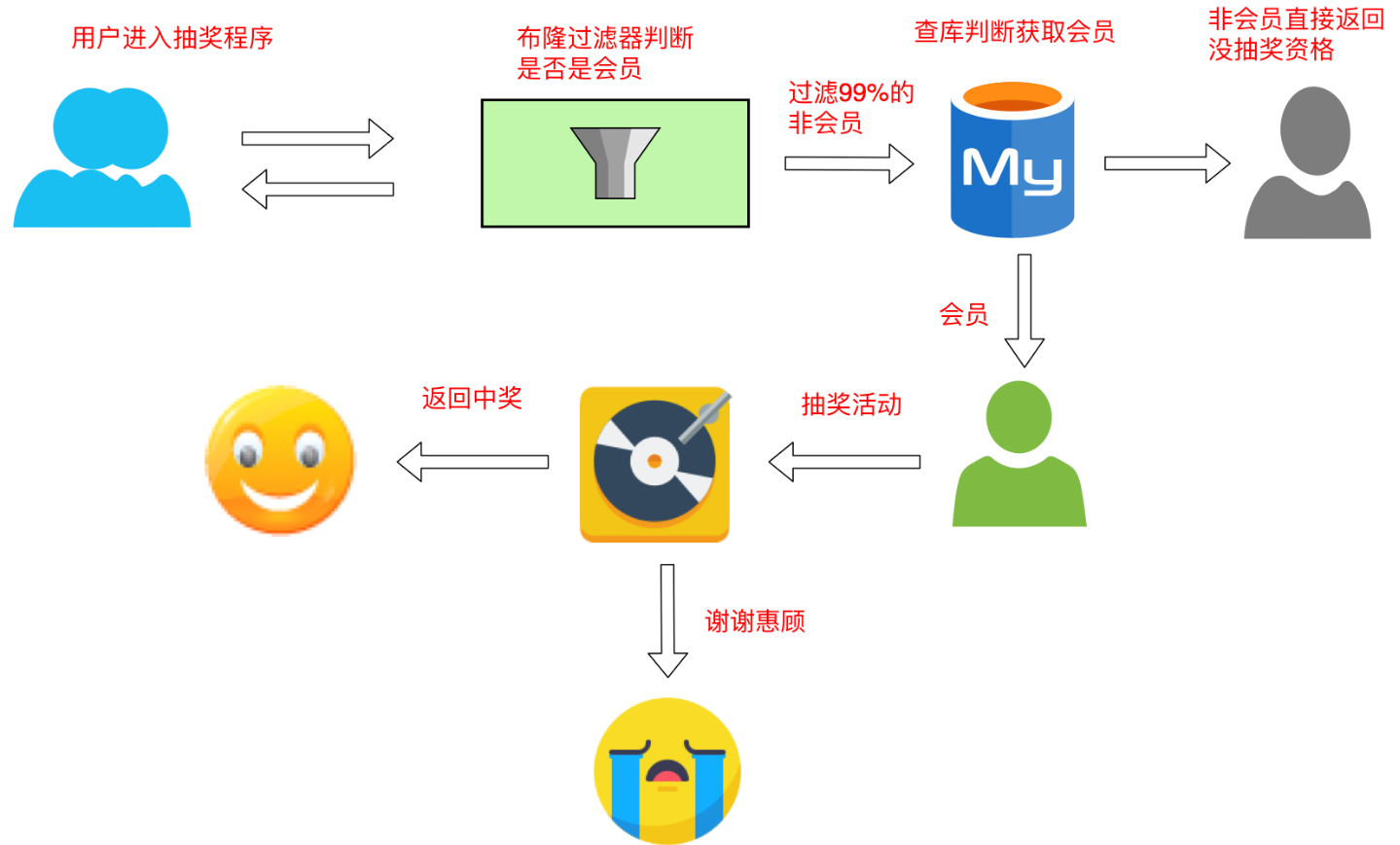
Google 布隆过滤器
布隆过滤器数据结构存放在 JVM 内存中。
引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
将数据库中的用户数据预加载到布隆过滤器中 Service 层
Controller
@RestController
public class BloomFilterController {
@Resource
private BloomFilterService bloomFilterService;
@RequestMapping("/bloom/idExists")
public boolean ifExists(int id){
return bloomFilterService.userIdExists(id);
}
}
测试
//测试发现 id 值为1~5 返回true,大于5则返回false,验证和数据库中的一致
http://192.168.31.230:8080/bloom/idExists?id=1
Google 布隆过滤器与 Redis 布隆过滤器
Google 布隆过滤器的缺陷
- 本地内存级别产物:数据量大的时候初始化过程缓慢。
- 重启即失效:无法持久化。
- 本地内存无法用于在分布式场景(无法实现 HA)。
- 不支持大数据存储:Google 布隆过滤器使用的是 JVM 的内存。
Redis 布隆过滤器优点
- 分布式
- 可扩展性 Bloom 过滤器:一旦 Bloom 过滤器达到容量,就会在其上创建一个新的过滤器
- 不存在重启即失效或者定时任务维护的成本
- 缺点:需要网络 IO,性能比基于内存的过滤器低。
Redis4.0 布隆过滤器安装过程
# 克隆和安装
$ git clone git://github.com/RedisLabsModules/rebloom
$ cd rebloom
$ make
# 将Rebloom加载到Redis中,在redis.conf里面添加
[root@localhost rebloom]# vim /test/redis-4.0.6/redis.conf
loadmodule /test/rebloom/redisbloom.so
# 启动Redis
[root@localhost rebloom]# /test/redis-4.0.6/src/redis-server /test/redis-4.0.6/redis.conf
# 验证Redis布隆过滤器是否安装成功
# 存值
[root@localhost rebloom]# /test/redis-4.0.6/src/redis-cli -p 6379 bf.add myBloom redis1
(integer) 1
[root@localhost rebloom]# /test/redis-4.0.6/src/redis-cli -p 6379 bf.add myBloom redis2
(integer) 1
[root@localhost rebloom]# /test/redis-4.0.6/src/redis-cli -p 6379 bf.add myBloom redis1
(integer) 0
# 取值
[root@localhost rebloom]# /test/redis-4.0.6/src/redis-cli -p 6379
127.0.0.1:6379> BF.EXISTS myBloom redis1
(integer) 1
127.0.0.1:6379> BF.EXISTS myBloom redis2
(integer) 1
127.0.0.1:6379> BF.EXISTS myBloom redis3
(integer) 0
SpringBoot 整合 Reids 布隆过滤器
RedisService 中(redisTemplate 的封装工具类)添加如下方法
public Boolean bloomFilterAdd(int value){
DefaultRedisScript<Boolean> bloomAdd = new DefaultRedisScript<>();
bloomAdd.setScriptSource(new ResourceScriptSource(new ClassPathResource("bloomFilterAdd.lua")));
bloomAdd.setResultType(Boolean.class);
List<Object> keyList= new ArrayList<>();
keyList.add(bloomFilterName);
keyList.add(value+"");
Boolean result = (Boolean) redisTemplate.execute(bloomAdd,keyList);
return result;
}
public Boolean bloomFilterExists(int value){
DefaultRedisScript<Boolean> bloomExists= new DefaultRedisScript<>();
bloomExists.setScriptSource(new ResourceScriptSource(new ClassPathResource("bloomFilterExist.lua")));
bloomExists.setResultType(Boolean.class);
List<Object> keyList= new ArrayList<>();
keyList.add(bloomFilterName);
keyList.add(value+"");
Boolean result = (Boolean) redisTemplate.execute(bloomExists,keyList);
return result;
}
bloomFilterAdd.lua
local bloomName = KEYS[1]
local value = KEYS[2]
-- bloomFilter
local result_1 = redis.call('BF.ADD', bloomName, value)
return result_1
bloomFilterExist.lua
local bloomName = KEYS[1]
local value = KEYS[2]
-- bloomFilter
local result_1 = redis.call('BF.EXISTS', bloomName, value)
return result_1
Controller
@RestController
public class BloomFilterController {
@Resource
private RedisService redisService;
@RequestMapping("/bloom/redisIdExists")
public boolean redisidExists(int id){
return redisService.bloomFilterExists(id);
}
@RequestMapping("/bloom/redisIdAdd")
public boolean redisidAdd(int id){
return redisService.bloomFilterAdd(id);
}
}
输出结果
# 添加三个数据
// http://192.168.31.230:8080/bloom/redisIdAdd?id=111
true
// http://192.168.31.230:8080/bloom/redisIdAdd?id=222
true
// http://192.168.31.230:8080/bloom/redisIdAdd?id=333
true
# 查询数据(发现布隆过滤器生效)
// http://192.168.31.230:8080/bloom/redisIdExists?id=111
true
// http://192.168.31.230:8080/bloom/redisIdExists?id=444
false